Now that my research project ‘Digital technologies and public procurement. Gatekeeping and experimentation in digital public governance’ nears its end, some outputs start to emerge. In this post, I would like to highlight two policy briefings summarising some of my top-level policy recommendations, and providing links to more detailed analysis. All materials are available in the ‘Digital Procurement Governance’ tab.


Digital procurement, PPDS and multi-speed datafication -- some thoughts on the March 2023 PPDS Communication
The 2020 European strategy for data ear-marked public procurement as a high priority area for the development of common European data spaces for public administrations. The 2020 data strategy stressed that
Public procurement data are essential to improve transparency and accountability of public spending, fighting corruption and improving spending quality. Public procurement data is spread over several systems in the Member States, made available in different formats and is not easily possible to use for policy purposes in real-time. In many cases, the data quality needs to be improved.
To address those issues, the European Commission was planning to ‘Elaborate a data initiative for public procurement data covering both the EU dimension (EU datasets, such as TED) and the national ones’ by the end of 2020, which would be ‘complemented by a procurement data governance framework’ by mid 2021.
With a 2+ year delay, details for the creation of the public procurement data space (PPDS) were disclosed by the European Commission on 16 March 2023 in the PPDS Communication. The procurement data governance framework is now planned to be developed in the second half of 2023.
In this blog post, I offer some thoughts on the PPDS, its functional goals, likely effects, and the quickly closing window of opportunity for Member States to support its feasibility through an ambitious implementation of the new procurement eForms at domestic level (on which see earlier thoughts here).
1. The PPDS Communication and its goals
The PPDS Communication sets some lofty ambitions aligned with those of the closely-related process of procurement digitalisation, which the European Commission in its 2017 Making Procurement Work In and For Europe Communication already saw as not only an opportunity ‘to streamline and simplify the procurement process’, but also ‘to rethink fundamentally the way public procurement, and relevant parts of public administrations, are organised … [to seize] a unique chance to reshape the relevant systems and achieve a digital transformation’ (at 11-12).
Following the same rhetoric of transformation, the PPDS Communication now stresses that ‘Integrated data combined with the use of state-of the-art and emerging analytics technologies will not only transform public procurement, but also give new and valuable insights to public buyers, policy-makers, businesses and interested citizens alike‘ (at 2). It goes further to suggest that ‘given the high number of ecosystems concerned by public procurement and the amount of data to be analysed, the impact of AI in this field has a potential that we can only see a glimpse of so far‘ (at 2).
The PPDS Communication claims that this data space ‘will revolutionise the access to and use of public procurement data:
It will create a platform at EU level to access for the first time public procurement data scattered so far at EU, national and regional level.
It will considerably improve data quality, availability and completeness, through close cooperation between the Commission and Member States and the introduction of the new eForms, which will allow public buyers to provide information in a more structured way.
This wealth of data will be combined with an analytics toolset including advanced technologies such as Artificial Intelligence (AI), for example in the form of Machine Learning (ML) and Natural Language Processing (NLP).’
A first comment or observation is that this rhetoric of transformation and revolution not only tends to create excessive expectations on what can realistically be delivered by the PPDS, but can also further fuel the ‘policy irresistibility’ of procurement digitalisation and thus eg generate excessive experimentation or investment into the deployment of digital technologies on the basis of such expectations around data access through PPDS (for discussion, see here). Policy-makers would do well to hold off on any investments and pilot projects seeking to exploit the data presumptively pooled in the PPDS until after its implementation. A closer look at the PPDS and the significant roadblocks towards its full implementation will shed further light on this issue.
2. What is the PPDS?
Put simply, the PPDS is a project to create a single data platform to bring into one place ‘all procurement data’ from across the EU—ie both data on above threshold contracts subjected to mandatory EU-wide publication through TED (via eForms from October 2023), and data on below threshold contracts, which publication may be required by the domestic laws of the Member States, or entirely voluntary for contracting authorities.
Given that above threshold procurement data is already (in the process of being) captured at EU level, the PPDS is very much about data on procurement not covered by the EU rules—which represents 80% of all public procurement contracts. As the PPDS Communication stresses
To unlock the full potential of public procurement, access to data and the ability to analyse it are essential. However, data from only 20% of all call for tenders as submitted by public buyers is available and searchable for analysis in one place [ie TED]. The remaining 80% are spread, in different formats, at national or regional level and difficult or impossible to re-use for policy, transparency and better spending purposes. In order (sic) words, public procurement is rich in data, but poor in making it work for taxpayers, policy makers and public buyers.

The PPDS thus intends to develop a ‘technical fix’ to gain a view on the below-threshold reality of procurement across the EU, by ‘pulling and pooling’ data from existing (and to be developed) domestic public contract registers and transparency portals. The PPDS is thus a mechanism for the aggregation of procurement data currently not available in (harmonised) machine-readable and structured formats (or at all).
As the PPDS Communication makes clear, it consists of four layers:
(1) A user interface layer (ie a website and/or app) underpinned by
(2) an analytics layer, which in turn is underpinned by (3) an integration layer that brings together and minimally quality-assures the (4) data layer sourced from TED, Member State public contract registers (including those at sub-national level), and data from other sources (eg data on beneficial ownership).
The two top layers condense all potential advantages of the PPDS, with the analytics layer seeking to develop a ‘toolset including emerging technologies (AI, ML and NLP)‘ to extract data insights for a multiplicity of purposes (see below 3), and the top user interface seeking to facilitate differential data access for different types of users and stakeholders (see below 4). The two bottom layers, and in particular the data layer, are the ones doing all the heavy lifting. Unavoidably, without data, the PPDS risks being little more than an empty shell. As always, ‘no data, no fun’ (see below 5).
Importantly, the top three layers are centralised and the European Commission has responsibility (and funding) for developing them, while the bottom data layer is decentralised, with each Member State retaining responsibility for digitalising its public procurement systems and connecting its data sources to the PPDS. Member States are also expected to bear their own costs, although there is EU funding available through different mechanisms. This allocation of responsibilities follows the limited competence of the EU in this area of inter-administrative cooperation, which unfortunately heightens the risks of the PPDS becoming little more than an empty shell, unless Member States really take the implementation of eForms and the collaborative approach to the construction of the PPDS seriously (see below 6).
The PPDS Communication foresees a progressive implementation of the PPDS, with the goal of having ‘the basic architecture and analytics toolkit in place and procurement data published at EU level available in the system by mid-2023. By the end of 2024, all participating national publication portals would be connected, historic data published at EU level integrated and the analytics toolkit expanded. As of 2025, the system could establish links with additional external data sources’ (at 2). It will most likely be delayed, but that is not very important in the long run—especially as the already accrued delays are the ones that pose a significant limitation on the adequate rollout of the PPDS (see below 6).
3. PPDS’ expected functionality
The PPDS Communication sets expectations around the functionality that could be extracted from the PPDS by different agents and stakeholders.
For public buyers, in addition to reducing the burden of complying with different types of (EU-mandated) reporting, the PPDS Communication expects that ‘insights gained from the PPDS will make it much easier for public buyers to
team up and buy in bulk to obtain better prices and higher quality;
generate more bids per call for tenders by making calls more attractive for bidders, especially for SMEs and start-ups;
fight collusion and corruption, as well as other criminal acts, by detecting suspicious patterns;
benchmark themselves more accurately against their peers and exchange knowledge, for instance with the aim of procuring more green, social and innovative products and services;
through the further digitalisation and emerging technologies that it brings about, automate tasks, bringing about considerable operational savings’ (at 2).
This largely maps onto my analysis of likely applications of digital technologies for procurement management, assuming the data is there (see here).
The PPDS Communication also expects that policy-makers will ‘gain a wealth of insights that will enable them to predict future trends‘; that economic operators, and SMEs in particular, ‘will have an easy-to-use portal that gives them access to a much greater number of open call for tenders with better data quality‘, and that ‘Citizens, civil society, taxpayers and other interested stakeholders will have access to much more public procurement data than before, thereby improving transparency and accountability of public spending‘ (at 2).
Of all the expected benefits or functionalities, the most important ones are those attributed to public buyers and, in particular, the possibility of developing ‘category management’ insights (eg potential savings or benchmarking), systems of red flags in relation to corruption and collusion risks, and the automation of some tasks. However, unlocking most of these functionalities is not dependent on the PPDS, but rather on the existence of procurement data at the ‘right’ level.
For example, category management or benchmarking may be more relevant or adequate (as well as more feasible) at national than at supra-national level, and the development of systems of red flags can also take place at below-EU level, as can automation. Importantly, the development of such functionalities using pan-EU data, or data concerning more than one Member State, could bias the tools in a way that makes them less suited, or unsuitable, for deployment at national level (eg if the AI is trained on data concerning solely jurisdictions other than the one where it would be deployed).
In that regard, the expected functionalities arising from PPDS require some further thought and it can well be that, depending on implementation (in particular in relation to multi-speed datafication, as below 5), Member States are better off solely using domestic data than that coming from the PPDS. This is to say that PPDS is not a solid reality and that its enabling character will fluctuate with its implementation.
4. Differential procurement data access through PPDS
As mentioned above, the PPDS Communication stresses that ‘Citizens, civil society, taxpayers and other interested stakeholders will have access to much more public procurement data than before, thereby improving transparency and accountability of public spending’ (at 2). However, this does not mean that the PPDS will be (entirely) open data.
The Communication itself makes clear that ‘Different user categories (e.g. Member States, public buyers, businesses, citizens, NGOs, journalists and researchers) will have different access rights, distinguishing between public and non-public data and between participating Member States that share their data with the PPDS (PPDS members, …) and those that need more time to prepare’ (at 8). Relatedly, ‘PPDS members will have access to data which is available within the PPDS. However, even those Member States that are not yet ready to participate in the PPDS stand to benefit from implementing the principles below, due to their value for operational efficiency and preparing for a more evidence-based policy’ (at 9). This raises two issues.
First, and rightly, the Communication makes clear that the PPDS moves away from a model of ‘fully open’ or ‘open by default’ procurement data, and that access to the PPDS will require differential permissioning. This is the correct approach. Regardless of the future procurement data governance framework, it is clear that the emerging thicket of EU data governance rules ‘requires the careful management of a system of multi-tiered access to different types of information at different times, by different stakeholders and under different conditions’ (see here). This will however raise significant issues for the implementation of the PPDS, as it will generate some constraints or disincentives for an ambitions implementation of eForms at national level (see below 6).
Second, and less clearly, the PPDS Communication evidences that not all Member States will automatically have equal access to PPDS data. The design seems to be such that Member States that do not feed data into PPDS will not have access to it. While this could be conceived as an incentive for all Member States to join PPDS, this outcome is by no means guaranteed. As above (3), it is not clear that Member States will be better off—in terms of their ability to extract data insights or to deploy digital technologies—by having access to pan-EU data. The main benefit resulting from pan-EU data only accrues collectively and, primarily, by means of facilitating oversight and enforcement by the European Commission. From that perspective, the incentives for PPDS participation for any given Member State may be quite warped or internally contradictory.
Moreover, given that plugging into PPDS is not cost-free, a Member State that developed a data architecture not immediately compatible with PPDS may well wonder whether it made sense to shoulder the additional costs and risks. From that perspective, it can only be hoped that the existence of EU funding and technical support will be maximised by the European Commission to offload that burden from the (reluctant) Member States. However, even then, full PPDS participation by all Member States will still not dispel the risk of multi-speed datafication.
5. No data, no fun — and multi-speed datafication
Related to the risk that some EU Member States will become PPDS members and others not, there is a risk (or rather, a reality) that not all PPDS members will equally contribute data—thus creating multi-speed datafication, even within the Member States that opt in to the PPDS.
First, the PPDS Communication makes it clear that ‘Member States will remain in control over which data they wish to share with the PPDS (beyond the data that must be published on TED under the Public Procurement Directives)‘ (at 7), It further specifies that ‘With the eForms, it will be possible for the first time to provide data in notices that should not be published, or not immediately. This is important to give assurance to public buyers that certain data is not made publicly available or not before a certain point in time (e.g. prices)’ (at 7, fn 17).
This means that each Member State will only have to plug whichever data it captures and decides to share into PPDS. It seems plain to see that this will result in different approaches to data capture, multiple levels of granularity, and varying approaches to restricting access to the date in the different Member States, especially bearing in mind that ‘eForms are not an “off the shelf” product that can be implemented only by IT developers. Instead, before developers start working, procurement policy decision-makers have to make a wide range of policy decisions on how eForms should be implemented’ in the different Member States (see eForms Implementation Handbook, at 9).
Second, the PPDS Communication is clear (in a footnote) that ‘One of the conditions for a successful establishment of the PPDS is that Member States put in place automatic data capture mechanisms, in a first step transmitting data from their national portals and contract registers’ (at 4, fn 10). This implies that Member States may need to move away from manually inputted information and that those seeking to create new mechanisms for automatic procurement data capture can take an incremental approach, which is very much baked into the PPDS design. This relates, for example, to the distinction between pre- and post-award procurement data, with pre-award data subjected to higher demands under EU law. It also relates to above and below threshold data, as only above threshold data is subjected to mandatory eForms compliance.
In the end, the extent to which a (willing) Member State will contribute data to the PPDS depends on its decisions on eForms implementation, which should be well underway given the October 2023 deadline for mandatory use (for above threshold contracts). Crucially, Member States contributing more data may feel let down when no comparable data is contributed to PPDS by other Member States, which can well operate as a disincentive to contribute any further data, rather than as an incentive for the others to match up that data.
6. Ambitious eForms implementation as the PPDS’ Achilles heel
As the analysis above has shown, the viability of the PPDS and its fitness for purpose (especially for EU-level oversight and enforcement purposes) crucially depends on the Member States deciding to take an ambitious approach to the implementation of eForms, not solely by maximising their flexibility for voluntary uses (as discussed here) but, crucially, by extending their mandatory use (under national law) to all below threshold procurement. It is now also clear that there is a need for as much homogeneity as possible in the implementation of eForms in order to guarantee that the information plugged into PPDS is comparable—which is an aspect of data quality that the PPDS Communication does not seem to have at all considered).
It seems that, due to competing timings, this poses a bit of a problem for the rollout of the PPDS. While eForms need to be fully implemented domestically by October 2023, the PPDS Communication suggests that the connection of national portals will be a matter for 2024, as the first part of the project will concern the top two layers and data connection will follow (or, at best, be developed in parallel). Somehow, it feels like the PPDS is being built without a strong enough foundation. It would be a shame (to put it mildly) if Member States having completed a transition to eForms by October 2023 were dissuaded from a second transition into a more ambitious eForms implementation in 2024 for the purposes of the PPDS.
Given that the most likely approach to eForms implementation is rather minimalistic, it can well be that the PPDS results in not much more than an empty shell with fancy digital analytics limited to very superficial uses. In that regard, the two-year delay in progressing the PPDS has created a very narrow (and quickly dwindling) window of opportunity for Member States to engage with an ambitions process of eForms implementation
7. Final thoughts
It seems to me that limited and slow progress will be attained under the PPDS in coming years. Given the undoubted value of harnessing procurement data, I sense that Member States will progress domestically, but primarily in specific settings such as that of their central purchasing bodies (see here). However, whether they will be onboarded into PPDS as enthusiastic members seems less likely.
The scenario seems to resemble limited voluntary cooperation in other areas (eg interoperability; for discussion see here). It may well be that the logic of EU competence allocation required this tentative step as a first move towards a more robust and proactive approach by the Commission in a few years, on grounds that the goal of creating the European data space could not be achieved through this less interventionist approach.
However, given the speed at which digital transformation could take place (and is taking place in some parts of the EU), and the rhetoric of transformation and revolution that keeps being used in this policy area, I can’t but feel let down by the approach in the PPDS Communication, which started with the decision to build the eForms on the existing regulatory framework, rather than more boldly seeking a reform of the EU procurement rules to facilitate their digital fitness.
Governing the Assessment and Taking of Risks in Digital Procurement Governance

In a previous blog post, I explored the main governance risks and legal obligations arising from the adoption of digital technologies, which revolve around data governance, algorithmic transparency, technological dependency, technical debt, cybersecurity threats, the risks stemming from the long-term erosion of the skills base in the public sector, and difficult trade-offs due to the uncertainty surrounding immature and still changing technologies within an also evolving regulatory framework. To address such risks and ensure compliance with the relevant governance obligations, I stressed the need to embed a comprehensive mechanism of risk assessment in the process of technological adoption.
In a new draft chapter (num 9) for my book project, I analyse how to embed risk assessments in the initial stages of decision-making processes leading to the adoption of digital solutions for procurement governance, and how to ensure that they are iterated throughout the lifecycle of use of digital technologies. To do so, I critically review the model of AI risk regulation that is emerging in the EU and the UK, which is based on self-regulation and self-assessment. I consider its shortcomings and how to strengthen the model, including the possibility of subjecting the process of technological adoption to external checks. The analysis converges with a broader proposal for institutionalised regulatory checks on the adoption of digital technologies by the public sector that I will develop more fully in another part of the book.
This post provides a summary of my main findings, on which I will welcome any comments: a.sanchez-graells@bristol.ac.uk. The full draft chapter is free to download: A Sanchez-Graells, ‘Governing the Assessment and Taking of Risks in Digital Procurement Governance’ to be included in A Sanchez-Graells, Digital Technologies and Public Procurement. Gatekeeping and experimentation in digital public governance (OUP, forthcoming), Available at SSRN: https://ssrn.com/abstract=4282882.
AI Risk Regulation
The emerging (global) model of AI regulation is risk-based—as opposed to a strict precautionary approach. This implies an assumption that ‘a technology will be adopted despite its harms’. This primarily means accepting that technological solutions may (or will) generate (some) negative impacts on public and private interests, even if it is not known when or how those harms will arise, or how extensive they will be. AI are unique, as they are ‘long-term, low probability, systemic, and high impact’, and ‘AI both poses “aggregate risks” across systems and low probability but “catastrophic risks to society”’ [for discussion, see Margot E Kaminski, ‘Regulating the risks of AI’ (2023) 103 Boston University Law Review, forthcoming]
This should thus trigger careful consideration of the ultimate implications of AI risk regulation, and advocates in favour of taking a robust regulatory approach—including to the governance of the risk regulation mechanisms put in place, which may well require external controls, potentially by an independent authority. By contrast, the emerging model of AI risk regulation in the context of procurement digitalisation in the EU and the UK leaves the adoption of digital technologies by public buyers largely unregulated and only subject to voluntary measures, or to open-ended obligations in areas without clear impact assessment standards (which reduces the prospect of effective mandatory enforcement).
Governance of Procurement Digitalisation in the EU
Despite the emergence of a quickly expanding set of EU digital law instruments imposing a patchwork of governance obligations on public buyers, whether or not they adopt digital technologies (see here), the primary decision whether to adopt digital technologies is not subject to any specific constraints, and the substantive obligations that follow from the diverse EU law instruments tend to refer to open-ended standards that require advanced technical capabilities to operationalise them. This would not be altered by the proposed EU AI Act.
Procurement-related AI uses are classified as minimal risk under the EU AI Act, which leaves them subject only to voluntary self-regulation via codes of conduct—yet to be developed. Such codes of conduct should encourage voluntary compliance with the requirements applicable to high-risk AI uses—such as risk management systems, data and data governance requirements, technical documentation, record-keeping, transparency, or accuracy, robustness and cybersecurity requirements—‘on the basis of technical specifications and solutions that are appropriate means of ensuring compliance with such requirements in light of the intended purpose of the systems.’ This seems to introduce a further element of proportionality or ‘adaptability’ requirement that could well water down the requirements applicable to minimal risk AI uses.
Importantly, while it is possible for Member States to draw such codes of conduct, the EU AI Act would pre-empt Member States from going further and mandating compliance with specific obligations (eg by imposing a blanket extension of the governance requirements designed for high-risk AI uses) across their public administrations. The emergent EU model is thus clearly limited to the development of voluntary codes of conduct and their likely content, while yet unknown, seems unlikely to impose the same standards applicable to the adoption of high-risk AI uses.
Governance of Procurement Digitalisation in the UK
Despite its deliberate light-touch approach to AI regulation and actively seeking to deviate from the EU, the UK is relatively advanced in the formulation of voluntary standards to govern procurement digitalisation. Indeed, the UK has adopted guidance for the use of AI in the public sector, and for AI procurement, and is currently piloting an algorithmic transparency standard (see here). The UK has also adopted additional guidance in the Digital, Data and Technology Playbook and the Technology Code of Practice. Remarkably, despite acknowledging the need for risk assessments—and even linking their conduct to spend approvals required for the acquisition of digital technologies by central government organisations—none of these instruments provides clear standards on how to assess (and mitigate) risks related to the adoption of digital technologies.
Thus, despite the proliferation of guidance documents, the substantive assessment of governance risks in digital procurement remains insufficiently addressed and left to undefined risk assessment standards and practices. The only exception concerns cyber security assessments, given the consolidated approach and guidance of the National Cyber Security Centre. This lack of precision in the substantive requirements applicable to data and algorithmic impact assessments clearly constrains the likely effectiveness of the UK’s approach to embedding technology-related impact assessments in the process of adoption of digital technologies for procurement governance (and, more generally, for public governance). In the absence of clear standards, data and algorithmic impact assessments will lead to inconsistent approaches and varying levels of robustness. The absence of standards will also increase the need to access specialist expertise to design and carry out the assessments. Developing such standards and creating an effective institutional mechanism to ensure compliance therewith thus remain a challenge.
The Need for Strengthened Digital Procurement Governance
Both in the EU and the UK, the emerging model of AI risk regulation leaves digital procurement governance to compliance with voluntary measures such as (future) codes of conduct or transparency standards or impose open-ended obligations in areas without clear standards (which reduces the prospect of effective mandatory enforcement). This follows general trends of AI risk regulation and evidences the emergence of a (sub)model highly dependent on self-regulation and self-assessment. This approach is rather problematic.
Self-Regulation: Outsourcing Impact Assessment Regulation to the Private Sector
The absence of mandatory standards for data and algorithmic impact assessments, as well as the embedded flexibility in the standards for cyber security, are bound to outsource the setting of the substantive requirements for those impact assessments to private vendors offering solutions for digital procurement governance. With limited public sector digital capability preventing a detailed specification of the applicable requirements, it is likely that these will be limited to a general obligation for tenderers to provide an impact assessment plan, perhaps by reference to emerging (international private) standards. This would imply the outsourcing of standard setting for risk assessments to private standard-setting organisations and, in the absence of those standards, to the tenderers themselves. This generates a clear and problematic risk of regulatory capture. Moreover, this process of outsourcing or excessively reliance on private agents to commercially determine impact assessments requirements is not sufficiently exposed to scrutiny and contestation.
Self-Assessment: Inadequacy of Mechanisms for Contestability and Accountability
Public buyers will rarely develop the relevant technological solutions but rather acquire them from technological providers. In that case, the duty to carry out the self-assessment will (or should be) cascaded down to the technology provider through contractual obligations. This would place the technology provider as ‘first party’ and the public buyer as ‘second party’ in relation to assuring compliance with the applicable obligations. In a setting of limited public sector digital capability, and in part as a result of a lack of clear standards providing an applicable benchmark (as above), the self-assessment of compliance with risk management requirements will either be de facto outsourced to private vendors (through a lack of challenge of their practices), or carried out by public buyers with limited capabilities (eg during the oversight of contract implementation). Even where public buyers have the required digital capabilities to carry out a more thorough analysis, they lack independence. ‘Second party’ assurance models unavoidably raise questions about their integrity due to the conflicting interests of the assurance provider who wants to use the system (ie the public buyer).
This ‘second party’ assurance model does not include adequate challenge mechanisms despite efforts to disclose (parts of) the relevant self-assessments. Such disclosures are constrained by general problems with ‘comply or explain’ information-based governance mechanisms, with the emerging model showing design features that have proven problematic in other contexts (such as corporate governance and financial market regulation). Moreover, there is no clear mechanism to contest the decisions to adopt digital technologies revealed by the algorithmic disclosures. In many cases, shortcomings in the risk assessments and the related minimisation and mitigation measures will only become observable after the materialisation of the underlying harms. For example, the effects of the adoption of a defective digital solution for decision-making support (eg a recommender system) will only emerge in relation to challengeable decisions in subsequent procurement procedures that rely on such solution. At that point, undoing the effects of the use of the tool may be impossible or excessively costly. In this context, challenges based on procedure-specific harms, such as the possibility to challenge discrete procurement decisions under the general rules on procurement remedies, are inadequate. Not least, because there can be negative systemic harms that are very hard to capture in the challenge to discrete decisions, or for which no agent with active standing has adequate incentives. To avoid potential harms more effectively, ex ante external controls are needed instead.
Creating External Checks on Procurement Digitalisation
It is thus necessary to consider the creation of external ex ante controls applicable to these decisions, to ensure an adequate embedding of effective risk assessments to inform (and constrain) them. Two models are worth considering: certification schemes and independent oversight.
Certification or Conformity Assessments
While not applicable to procurement uses, the model of conformity assessment in the proposed EU AI Act offers a useful blueprint. The main potential shortcoming of conformity assessment systems is that they largely rely on self-assessments by the technology vendors, and thus on first party assurance. Third-party certification (or algorithmic audits) is possible, but voluntary. Whether there would be sufficient (market) incentives to generate a broad (voluntary) use of third-party conformity assessments remains to be seen. While it could be hoped that public buyers could impose the use of certification mechanisms as a condition for participation in tender procedures, this is a less than guaranteed governance strategy given the EU procurement rules’ functional approach to the use of labels and certificates—which systematically require public buyers to accept alternative means of proof of compliance. This thus seems to offer limited potential for (voluntary) certification schemes in this specific context.
Relatedly, the conformity assessment system foreseen in the EU AI Act is also weakened by its reliance on vague concepts with non-obvious translation into verifiable criteria in the context of a third-party assurance audit. This can generate significant limitations in the conformity assessment process. This difficulty is intended to be resolved through the development of harmonised standards by European standardisation organisations and, where those do not exist, through the approval by the European Commission of common specifications. However, such harmonised standards will largely create the same risks of commercial regulatory capture mentioned above.
Overall, the possibility of relying on ‘third-party’ certification schemes offers limited advantages over the self-regulatory approach.
Independent External Oversight
Moving beyond the governance limitations of voluntary third-party certification mechanisms and creating effective external checks on the adoption of digital technologies for procurement governance would require external oversight. An option would be to make the envisaged third-party conformity assessments mandatory, but that would perpetuate the risks of regulatory capture and the outsourcing of the assurance system to private parties. A different, preferable option would be to assign the approval of the decisions to adopt digital technologies and the verification of the relevant risks assessments to a centralised authority also tasked with setting the applicable requirements therefor. The regulator would thus be placed as gatekeeper of the process of transition to digital procurement governance, instead of the atomised imposition of this role on public buyers. This would be reflective of the general features of the system of external controls proposed in the US State of Washington’s Bill SB 5116 (for discussion, see here).
The main goal would be to introduce an element of external verification of the assessment of potential AI harms and the related taking of risks in the adoption of digital technologies. It is submitted that there is a need for the regulator to be independent, so that the system fully encapsulates the advantages of third-party assurance mechanisms. It is also submitted that the data protection regulator may not be best placed to take on the role as its expertise—even if advanced in some aspects of data-intensive digital technologies—primarily relates to issues concerning individual rights and their enforcement. The more diffuse collective interests at stake in the process of transition to a new model of public digital governance (not only in procurement) would require a different set of analyses. While reforming data protection regulators to become AI mega-regulators could be an option, that is not necessarily desirable and it seems that an easier to implement, incremental approach would involve the creation of a new independent authority to control the adoption of AI in the public sector, including in the specific context of procurement digitalisation.
Conclusion
An analysis of emerging regulatory approaches in the EU and the UK shows that the adoption of digital technologies by public buyers is largely unregulated and only subjected to voluntary measures, or to open-ended obligations in areas without clear standards (which reduces the prospect of effective mandatory enforcement). The emerging model of AI risk regulation in the EU and UK follows more general trends and points at the consolidation of a (sub)model of risk-based digital procurement governance that strongly relies on self-regulation and self-assessment.
However, given its limited digital capabilities, the public sector is not best placed to control or influence the process of self-regulation, which results in the outsourcing of crucial regulatory tasks to technology vendors and the consequent risk of regulatory capture and suboptimal design of commercially determined governance mechanisms. These risks are compounded by the emerging ‘second party assurance’ model, as self-assessments by technology vendors would not be adequately scrutinised by public buyers, either due to a lack of digital capabilities or the unavoidable structural conflicts of interest of assurance providers with an interest in the use of the technology, or both. This ‘second party’ assurance model does not include adequate challenge mechanisms despite efforts to disclose (parts of) the relevant self-assessments. Such disclosures are constrained by general problems with ‘comply or explain’ information-based governance mechanisms, with the emerging model showing design features that have proven problematic in other contexts (such as corporate governance and financial market regulation). Moreover, there is no clear mechanism to contest the decisions revealed by the disclosures, including in the context of (delayed) specific uses of the technological solutions.
The analysis also shows how a model of third-party assurance or certification would be affected by the same issues of outsourcing of regulatory decisions to private parties, and ultimately would largely replicate the shortcomings of the self-regulatory and self-assessed model. A certification model would thus only generate a marginal improvement over the emerging model—especially given the functional approach to the use of certification and labels in procurement.
Moving past these shortcomings requires assigning the approval of decisions whether to adopt digital technologies and the verification of the related impact assessments to an independent authority: the ‘AI in the Public Sector Authority’ (AIPSA). I will fully develop a proposal for such authority in coming months.
Registration open: TECH FIXES FOR PROCUREMENT PROBLEMS?
As previously announced, on 15 December, I will have the chance to discuss my ongoing research on procurement digitalisation with a stellar panel: Eliza Niewiadomska (EBRD), Jessica Tillipman (GW Law), and Sope Williams (Stellenbosch).
The webinar will provide an opportunity to take a hard look at the promise of tech fixes for procurement problems, focusing on key issues such as:
The ‘true’ potential of digital technologies in procurement.
The challenges arising from putting key enablers in place, such as an adequate big data architecture and access to digital skills in short supply.
The challenges arising from current regulatory frameworks and constraints not applicable to the private sector.
New challenges posed by data governance and cybersecurity risks.
The webinar will be held on December 15, 2022 at 9:00 am EST / 2:00 pm GMT / 3:00 pm CET-SAST. Full details and registration at: https://blogs.gwu.edu/law-govpro/tech-fixes-for-procurement-problems/.

Save the date: 15 Dec, Tech fixes for procurement problems?
If you are interested in procurement digitalisation, please save the date for an online workshop on ‘Tech fixes for procurement problems?’ on 15 December 2022, 2pm GMT. I will have the chance to discuss my ongoing research (scroll down for a few samples) with a stellar panel: Eliza Niewiadomska (EBRD), Jessica Tillipman (GW Law), and Sope Williams (Stellenbosch). We will also have plenty time for a conversation with participants. Do not let other commitments get on the way of joining the discussion!
More details and registration coming soon. For any questions, please email me: a.sanchez-graells@bristol.ac.uk.

Digital technologies, hype, and public sector capability

© Martin Brandt / Flickr.
By Albert Sanchez-Graells (@How2CrackANut) and Michael Lewis (@OpsProf).*
The public sector’s reaction to digital technologies and the associated regulatory and governance challenges is difficult to map, but there are some general trends that seem worrisome. In this blog post, we reflect on the problematic compound effects of technology hype cycles and diminished public sector digital technology capability, paying particular attention to their impact on public procurement.
Digital technologies, smoke, and mirrors
There is a generalised over-optimism about the potential of digital technologies, as well as their likely impact on economic growth and international competitiveness. There is also a rush to ‘look digitally advanced’ eg through the formulation of ‘AI strategies’ that are unlikely to generate significant practical impacts (more on that below). However, there seems to be a big (and growing?) gap between what countries report (or pretend) to be doing (eg in reports to the OECD AI observatory, or in relation to any other AI readiness ranking) and what they are practically doing. A relatively recent analysis showed that European countries (including the UK) underperform particularly in relation to strategic aspects that require detailed work (see graph). In other words, there are very few countries ready to move past signalling a willingness to jump onto the digital tech bandwagon.
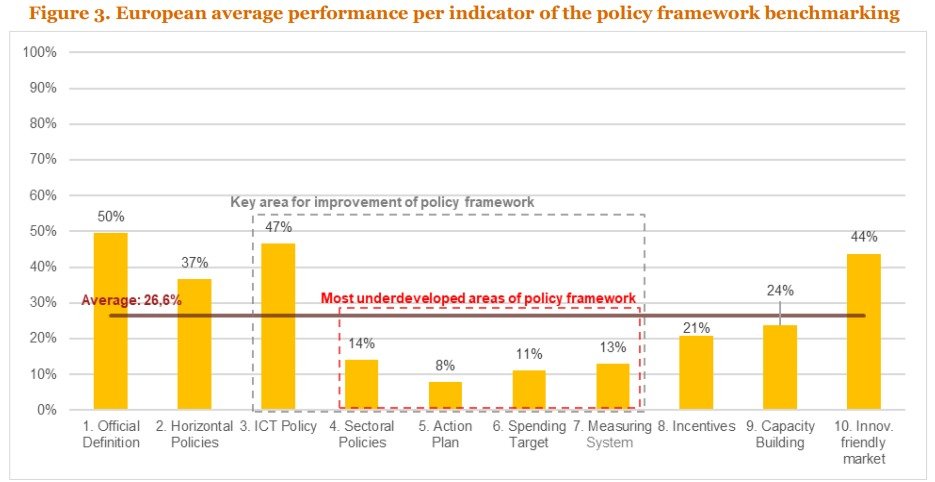
Source: PWC, The strategic use of public procurement for innovation in the digital economy (2021: 9).
Some of that over-optimism stems from limited public sector capability to understand the technologies themselves (as well as their implications), which leads to naïve or captured approaches to policymaking (on capture, see the eye-watering account emerging from the #Uberfiles). Given the closer alignment (or political meddling?) of policymakers with eg research funding programmes, including but not limited to academic institutions, naïve or captured approaches impact other areas of ‘support’ for the development of digital technologies. This also trickles down to procurement, as the ‘purchasing’ of digital technologies with public money is seen as a (not very subtle) way of subsidising their development (nb. there are many proponents of that approach, such as Mazzucato, as discussed here). However, this can also generate further space for capture, as the same lack of capability that affects high(er) level policymaking also affects funding organisations and ‘street level’ procurement teams. This results in a situation where procurement best practices such as market engagement result in the ‘art of the possible’ being determined by private industry. There is rarely co-creation of solutions, but too often a capture of procurement expenditure by entrepreneurs.
Limited capability, difficult assessments, and dependency risk
Perhaps the universalist techno-utopian framing (cost savings and efficiency and economic growth and better health and new service offerings, etc.) means it is increasingly hard to distinguish the specific merits of different digitalisation options – and the commercial interests that actively hype them. It is also increasingly difficult to carry out effective impact assessments where the (overstressed) benefits are relatively narrow and short-termist, while the downsides of technological adoption are diffuse and likely to only emerge after a significant time lag. Ironically, this limited ability to diagnose ‘relative’ risks and rewards is further exacerbated by the diminishing technical capability of the state: a negative mirror to Amazon’s flywheel model for amplifying capability. Indeed, as stressed by Bharosa (2022): “The perceptions of benefits and risks can be blurred by the information asymmetry between the public agencies and GovTech providers. In the case of GovTech solutions using new technologies like AI, Blockchain and IoT, the principal-agent problem can surface”.
As Colington (2021) points out, despite the “innumerable papers in organisation and management studies” on digitalisation, there is much less understanding of how interests of the digital economy might “reconfigure” public sector capacity. In studying Denmark’s policy of public sector digitalisation – which had the explicit intent of stimulating nascent digital technology industries – she observes the loss of the very capabilities necessary “for welfare states to develop competences for adapting and learning”. In the UK, where it might be argued there have been attempts, such as the Government Digital Services (GDS) and NHS Digital, to cultivate some digital skills ‘in-house’, the enduring legacy has been more limited in the face of endless demands for ‘cost saving’. Kattel and Takala (2021) for example studied GDS and noted that, despite early successes, they faced the challenge of continual (re)legitimization and squeezed investment; especially given the persistent cross-subsidised ‘land grab’ of platforms, like Amazon and Google, that offer ‘lower cost and higher quality’ services to governments. The early evidence emerging from the pilot algorithmic transparency standard seems to confirm this trend of (over)reliance on external providers, including Big Tech providers such as Microsoft (see here).
This is reflective of Milward and Provan’s (2003) ‘hollow state’ metaphor, used to describe "the nature of the devolution of power and decentralization of services from central government to subnational government and, by extension, to third parties – nonprofit agencies and private firms – who increasingly manage programs in the name of the state.” Two decades after its formulation, the metaphor is all the more applicable, as the hollowing out of the State is arguably a few orders of magnitude larger due the techno-centricity of reforms in the race towards a new model of digital public governance. It seems as if the role of the State is currently understood as being limited to that of enabler (and funder) of public governance reforms, not solely implemented, but driven by third parties—and primarily highly concentrated digital tech giants; so that “some GovTech providers can become the next Big Tech providers that could further exploit the limited technical knowledge available at public agencies [and] this dependency risk can become even more significant once modern GovTech solutions replace older government components” (Bharosa, 2022). This is a worrying trend, as once dominance is established, the expected anticompetitive effects of any market can be further multiplied and propagated in a setting of low public sector capability that fuels risk aversion, where the adage “Nobody ever gets fired for buying IBM” has been around since the 70s with limited variation (as to the tech platform it is ‘safe to engage’).
Ultimately, the more the State takes a back seat, the more its ability to steer developments fades away. The rise of a GovTech industry seeking to support governments in their digital transformation generates “concerns that GovTech solutions are a Trojan horse, exploiting the lack of technical knowledge at public agencies and shifting decision-making power from public agencies to market parties, thereby undermining digital sovereignty and public values” (Bharosa, 2022). Therefore, continuing to simply allow experimentation in the GovTech market without a clear strategy on how to reign the industry in—and, relatedly, how to build the public sector capacity needed to do so as a precondition—is a strategy with (exponentially) increasing reversal costs and an unclear tipping point past which meaningful change may simply not be possible.
Public sector and hype cycle
Being more pragmatic, the widely cited, if impressionistic, “hype cycle model” developed by Gartner Inc. provides additional insights. The model presents a generalized expectations path that new technologies follow over time, which suggests that new industrial technologies progress through different stages up to a peak that is followed by disappointment and, later, a recovery of expectations.

Although intended to describe aggregate technology level dynamics, it can be useful to consider the hype cycle for public digital technologies. In the early phases of the curve, vendors and potential users are actively looking for ways to create value from new technology and will claim endless potential use cases. If these are subsequently piloted or demonstrated – even if ‘free’ – they are exciting and visible, and vendors are keen to share use cases, they contribute to creating hype. Limited public sector capacity can also underpin excitement for use cases that are so far removed from their likely practical implementation, or so heavily curated, that they do not provide an accurate representation of how the technology would operate at production phase in the generally messy settings of public sector activity and public sector delivery. In phases such as the peak of inflated expectations, only organisations with sufficient digital technology and commercial capabilities can see through sophisticated marketing and sales efforts to separate the hype from the true potential of immature technologies. The emperor is likely to be naked, but who’s to say?
Moreover, as mentioned above, international organisations one step (upwards) removed from the State create additional fuel for the hype through mapping exercises and rankings, which generate a vicious circle of “public sector FOMO” as entrepreneurial bureaucrats and politicians are unlikely to want to be listed bottom of the table and can thus be particularly receptive to hyped pitches. This can leverage incentives to support *almost any* sort of tech pilots and implementations just to be seen to do something ‘innovative’, or to rush through high-risk implementations seeking to ‘cash in’ on the political and other rents they can (be spun to) generate.
However, as emerging evidence shows (AI Watch, 2022), there is a big attrition rate between announced and piloted adoptions, and those that are ultimately embedded in the functioning of the public sector in a value-adding manner (ie those that reach the plateau of productivity stage in the cycle). Crucially, the AI literacy and skills in the staff involved in the use of the technology post-pilot are one of the critical challenges to the AI implementation phase in the EU public sector (AI Watch, 2021). Thus, early moves in the hype curve are unlikely to translate into sustainable and expectations-matching deployments in the absence of a significant boost of public sector digital technology capabilities. Without committed long-term investment in that capability, piloting and experimentation will rarely translate into anything but expensive pet projects (and lucrative contracts).
Locking the hype in: IP, data, and acquisitions markets
Relatedly, the lack of public sector capacity is a foundation for eg policy recommendations seeking to avoid the public buyer acquiring (and having to manage) IP rights over the digital technologies it funds through procurement of innovation (see eg the European Commission’s policy approach: “There is also a need to improve the conditions for companies to protect and use IP in public procurement with a view to stimulating innovation and boosting the economy. Member States should consider leaving IP ownership to the contractors where appropriate, unless there are overriding public interests at stake or incompatible open licensing strategies in place” at 10).
This is clear as mud (eg what does overriding public interest mean here?) but fails to establish an adequate balance between public funding and public access to the technology, as well as generating (unavoidable?) risks of lock-in and exacerbating issues of lack of capacity in the medium and long-term. Not only in terms of re-procuring the technology (see related discussion here), but also in terms of the broader impact this can have if the technology is propagated to the private sector as a result of or in relation to public sector adoption.
Linking this recommendation to the hype curve, such an approach to relying on proprietary tech with all rights reserved to the third-party developer means that first mover advantages secured by private firms at the early stages of the emergence of a new technology are likely to be very profitable in the long term. This creates further incentives for hype and for investment in being the first to capture decision-makers, which results in an overexposure of policymakers and politicians to tech entrepreneurs pushing hard for (too early) adoption of technologies.
The exact same dynamic emerges in relation to access to data held by public sector entities without which GovTech (and other types of) innovation cannot take place. The value of data is still to be properly understood, as are the mechanisms that can ensure that the public sector obtains and retains the value that data uses can generate. Schemes to eg obtain value options through shares in companies seeking to monetise patient data are not bullet-proof, as some NHS Trusts recently found out (see here, and here paywalled). Contractual regulation of data access, data ownership and data retention rights and obligations pose a significant challenge to institutions with limited digital technology capabilities and can compound IP-related lock-in problems.
A final further complication is that the market for acquisitions of GovTech and other digital technologies start-ups and scale-ups is very active and unpredictable. Even with standard levels of due diligence, public sector institutions that had carefully sought to foster a diverse innovation ecosystem and to avoid contracting (solely) with big players may end up in their hands anyway, once their selected provider leverages their public sector success to deliver an ‘exit strategy’ for their founders and other (venture capital) investors. Change of control clauses clearly have a role to play, but the outside alternatives for public sector institutions engulfed in this process of market consolidation can be limited and difficult to assess, and particularly challenging for organisations with limited digital technology and associated commercial capabilities.
Procurement at the sharp end
Going back to the ongoing difficulty (and unwillingness?) in regulating some digital technologies, there is a (dominant) general narrative that imposes a ‘balanced’ approach between ensuring adequate safeguards and not stifling innovation (with some countries clearly erring much more on the side of caution, such as the UK, than others, such as the EU with the proposed EU AI Act, although the scope of application of its regulatory requirements is narrower than it may seem). This increasingly means that the tall order task of imposing regulatory constraints on the digital technologies and the private sector companies that develop (and own them) is passed on to procurement teams, as the procurement function is seen as a useful regulatory mechanism (see eg Select Committee on Public Standards, Ada Lovelace Institute, Coglianese and Lampmann (2021), Ben Dor and Coglianese (2022), etc but also the approach favoured by the European Commission through the standard clauses for the procurement of AI).
However, this approach completely ignores issues of (lack of) readiness and capability that indicate that the procurement function is being set up to fail in this gatekeeping role (in the absence of massive investment in upskilling). Not only because it lacks the (technical) ability to figure out the relevant checks and balances, and because the levels of required due diligence far exceed standard practices in more mature markets and lower risk procurements, but also because the procurement function can be at the sharp end of the hype cycle and (pragmatically) unable to stop the implementation of technological deployments that are either wasteful or problematic from a governance perspective, as public buyers are rarely in a position of independent decision-making that could enable them to do so. Institutional dynamics can be difficult to navigate even with good insights into problematic decisions, and can be intractable in a context of low capability to understand potential problems and push back against naïve or captured decisions to procure specific technologies and/or from specific providers.
Final thoughts
So, as a generalisation, lack of public sector capability seems to be skewing high level policy and limiting the development of effective plans to roll it out, filtering through to incentive systems that will have major repercussions on what technologies are developed and procured, with risks of lock-in and centralisation of power (away from the public sector), as well as generating a false comfort in the ability of the public procurement function to provide an effective route to tech regulation. The answer to these problems is both evident, simple, and politically intractable in view of the permeating hype around new technologies: more investment in capacity building across the public sector.
This regulatory answer is further complicated by the difficulty in implementing it in an employment market where the public sector, its reward schemes and social esteem are dwarfed by the high salaries, flexible work conditions and allure of the (Big) Tech sector and the GovTech start-up scene. Some strategies aimed at alleviating the generalised lack of public sector capability, e.g. through a GovTech platform at the EU level, can generate further risks of reduction of (in-house) public sector capability at State (and regional, local) level as well as bottlenecks in the access of tech to the public sector that could magnify issues of market dominance, lock-in and over-reliance on GovTech providers (as discussed in Hoekstra et al, 2022).
Ultimately, it is imperative to build more digital technology capability in the public sector, and to recognise that there are no quick (or cheap) fixes to do so. Otherwise, much like with climate change, despite the existence of clear interventions that can mitigate the problem, the hollowing out of the State and the increasing overdependency on Big Tech providers will be a self-fulfilling prophecy for which governments will have no one to blame but themselves.
___________________________________
* We are grateful to Rob Knott (@Procure4Health) for comments on an earlier draft. Any remaining errors and all opinions are solely ours.
Algorithmic transparency: some thoughts on UK's first four published disclosures and the standards' usability

© Fabrice Jazbinsek / Flickr.
The Algorithmic Transparency Standard (ATS) is one of the UK’s flagship initiatives for the regulation of public sector use of artificial intelligence (AI). The ATS encourages (but does not mandate) public sector entities to fill in a template to provide information about the algorithmic tools they use, and why they use them [see e.g. Kingsman et al (2022) for an accessible overview].
The ATS is currently being piloted, and has so far resulted in the publication of four disclosures relating to the use of algorithms in different parts of the UK’s public sector. In this post, I offer some thoughts based on these initial four disclosures, in particular from the perspective of the usability of the ATS in facilitating an enhanced understanding of AI use cases, and accountability for those.
The first four disclosed AI use cases
The ATS pilot has so far published information in two batches (on 1 June and 6 July 2022), comprising the following four AI use cases:
Within Cabinet Office, the GOV.UK Data Labs team piloted the ATS for their Related Links tool; a recommendation engine built to aid navigation of GOV.UK (the primary UK central government website) by providing relevant onward journeys from a content page, with the aim of helping users find useful information and content, aiding navigation.
In the Department for Health and Social Care and NHS Digital, the QCovid team piloted the ATS with a COVID-19 clinical tool used to predict how at risk individuals might be from COVID-19. The tool was developed for use by clinicians in support of conversations with patients about personal risk, and it uses algorithms to combine a number of factors such as age, sex, ethnicity, height and weight (to calculate BMI), and specific health conditions and treatments in order to estimate the combined risk of catching coronavirus and being hospitalised or catching coronavirus and dying. Importantly, “The original version of the QCovid algorithms were also used as part of the Population Risk Assessment to add patients to the Shielded Patient List in February 2021. These patients were advised to shield at that time were provided support for doing so, and were prioritised for COVID-19 vaccination.”
The Information Commissioner's Office has piloted the ATS with its Registration Inbox AI, which uses a machine learning algorithm to categorise emails sent to the Information Commissioner's Office’s registration inbox and to send out an auto-reply where the algorithm “detects … a request about changing a business address. In cases where it detects this kind of request, the algorithm sends out an autoreply that directs the customer to a new online service and points out further information required to process a change request. Only emails with an 80% certainty of a change of address request will be sent an email containing the link to the change of address form.”
The Food Standards Agency piloted the ATS with its Food Hygiene Rating Scheme (FHRS) – AI, which is an algorithmic tool to help local authorities to prioritise inspections of food businesses based on their predicted food hygiene rating by predicting which establishments might be at a higher risk of non-compliance with food hygiene regulations. Importantly, the tool is of voluntary use and “it is not intended to replace the current approach to generate a FHRS score. The final score will always be the result of an inspection undertaken by [a local authority] officer.”
Harmless (?) use cases
At first glance, and on the basis of the implications of the outcome of the algorithmic recommendation, it would seem that the four use cases are relatively harmless, i.e..
If GOV.UK recommends links to content that is not relevant or helpful, the user may simply ignore them.
The outcome of the QCovid tool simply informs the GPs’ (or other clinicians’) assessment of the risk of their patients, and the GPs’ expertise should mediate any incorrect (either over-inclusive, or under-inclusive) assessments by the AI.
If the ICO sends an automatic email with information on how to change their business address to somebody that had submitted a different query, the receiver can simply ignore that email.
Incorrect or imperfect prioritisation of food businesses for inspection could result in the early inspection of a low-risk restaurant, or the late(r) inspection of a higher-risk restaurant, but this is already a risk implicit in allowing restaurants to open pending inspection; AI does not add risk.
However, this approach could be too simplistic or optimistic. It can be helpful to think about what could really happen if the AI got it wrong ‘in a disaster scenario’ based on possible user reactions (a useful approach promoted by the Data Hazards project). It seems to me that, on ‘worse case scenario’ thinking (and without seeking to be exhaustive):
If GOV.UK recommends content that is not helpful but is confusing, the user can either engage in red tape they did not need to complete (wasting both their time and public resources) or, worse, feel overwhelmed, confused or misled and abandon the administrative interaction they were initially seeking to complete. This can lead to exclusion from public services, and be particularly problematic if these situations can have a differential impact on different user groups.
There could be over-reliance on the QCovid algorithm by (too busy) GPs. This could lead to advising ‘as a matter of routine’ the taking of excessive precautions with significant potential impacts on the day to day lives of those affected—as was arguably the case for some of the citizens included in shielding categories in the earlier incarnation of the algorithm. Conversely, GPs that identified problems in the early use of the algorithm could simply ignore it, thus potentially losing the benefits of the algorithm in other cases where it could have been helpful—potentially leading to under-precaution by individuals that could have otherwise been better safeguarded.
Similarly to 1, the provision of irrelevant and potentially confusing information can lead to waste of resource (e.g. users seeking to change their business registration address because they wrongly think it is a requirement to process their query or, at a lower end of the scale, users having to read and consider information about an administrative process they have no interest in). Beyond that, the classification algorithm could generate loss of queries if there was no human check to verify that the AI classification was correct. If this check takes place anyway, the advantages of automating the sending of the initial email seem rather marginal.
Similar to 2, the incorrect prediction of risk can lead to misuse of resources in the carrying out of inspections by local authorities, potentially pushing down the list of restaurants pending inspection some that are high-risk and that could thus be seen their inspection repeatedly delayed. This could have important public health implications, at least for those citizens using the to be inspected restaurants for longer than they would otherwise have. Conversely, inaccurate prioritisations that did not seem to catch more ‘risky’ restaurants could also lead to local authorities abandoning its use. There is also a risk of profiling of certain types of businesses (and their owners), which could lead to victimisation if the tool was improperly used, or used in relation to restaurants that have been active for a longer period (eg to trigger fresh (re)inspections).
No AI application is thus entirely harmless. Of course, this is just a matter of theoretical speculation—as could also be speculated whether reduced engagement with the AI would generate a second tier negative effect, eg if ‘learning’ algorithms could not be revised and improved on the basis of ‘real-life’ feedback on whether their predictions were or not accurate.
I think that this sort of speculation offers a useful yardstick to assess the extent to which the ATS can be helpful and usable. I would argue that the ATS will be helpful to the extent that (a) it provides information susceptible of clarifying whether the relevant risks have been taken into account and properly mitigated or, failing that (b) it provides information that can be used to challenge the insufficiency of any underlying risk assessments or mitigation strategies. Ultimately, AI transparency is not an end in itself, but simply a means of increasing accountability—at least in the context of public sector AI adoption. And it is clear that any degree of transparency generated by the ATS will be an improvement on the current situation, but is the ATS really usable?
Finding out more on the basis of the ATS disclosures
To try to answer that general question on whether the ATS is usable and serves to facilitate increased accountability, I have read the four disclosures in full. Here is my summary/extracts of the relevant bits for each of them.
GOV.UK Related Links
Since May 2019, the tool has been using an algorithm called node2vec (machine learning algorithm that learns network node embeddings) to train a model on the last three weeks of user movement data (web analytics data). The benefits are described as “the tool … predicts related links for a page. These related links are helpful to users. They help users find the content they are looking for. They also help a user find tangentially related content to the page they are on; it’s a bit like when you are looking for a book in the library, you might find books that are relevant to you on adjacent shelves.“
The way the tool works is described in some more detail: “The tool updates links every three weeks and thus tracks changes in user behaviour.” “Every three weeks, the machine learning algorithm is trained using the last three weeks of analytics data and trains a model that outputs related links that are published, overwriting the existing links with new ones.” “The average click through rate for related links is about 5% of visits to a content page. For context, GOV.UK supports an average of 6 million visits per day (Jan 2022). True volumes are likely higher owing to analytics consent tracking. We only track users who consent to analytics cookies …”.
The decision process is fully automated, but there is “a way for publishers to add/amend or remove a link from the component. On average this happens two or three times a month.” “Humans have the capability to recommend changes to related links on a page. There is a process for links to be amended manually and these changes can persist. These human expert generated links are preferred to those generated by the model and will persist.” Moreover, “GOV.UK has a feedback link, “report a problem with this page”, on every page which allows users to flag incorrect links or links they disagree with.” The tool was subjected to a Data Protection Impact Assessment (DPIA), but no other impact assessments (IAs) are listed.
When it comes to risk identification and mitigation, the disclosure indicates: “A recommendation engine can produce links that could be deemed wrong, useless or insensitive by users (e.g. links that point users towards pages that discuss air accidents).” and that, as mitigation: “We added pages to a deny list that might not be useful for a user (such as the homepage) or might be deemed insensitive (e.g. air accident reports). We also enabled publishers or anyone with access to the tagging system to add/amend or remove links. GOV.UK users can also report problems through the feedback mechanisms on GOV.UK.“
Overall, then, the risk I had identified is only superficially identified, in that the ATS disclosure does not show awareness of the potential differing implications of incorrect or useless recommendations across the spectrum. The narrative equating the recommendations to browsing the shelves of a library is quite suggestive in that regard, as is the fact that the quality controls are rather limited.
Indeed, it seems that the quality control mechanisms require a high level of effort by every publisher, as they need to check every three weeks whether the (new) related links appearing in each of the pages they publish are relevant and unproblematic. This seems to have reversed the functional balance of convenience. Before the implementation of the tool, only approximately 2,000 out of 600,000 pieces of content on GOV.UK had related links, as they had to be created manually (and thus, hopefully, were relevant, if not necessarily unproblematic). Now, almost all pages have up to five related content suggestions, but only two or three out of 600,000 pages see their links manually amended per month. A question arises whether this extremely low rate of manual intervention is reflective of the high quality of the system, or the reverse evidence of lack of resource to quality-assure websites that previously prevented 98% of pages from having this type of related information.
However, despite the queries as to the desirability of the AI implementation as described, the ATS disclosure is in itself useful because it allows the type of analysis above and, in case someone considers the situation unsatisfactory or would like to prove it further, there are is a clear gateway to (try to) engage the entity responsible for this AI deployment.
QCovid algorithm
The algorithm was developed at the onset of the Covid-19 pandemic to drive government decisions on which citizens to advise to shield, support during shielding, and prioritise for vaccination rollout. Since the end of the shielding period, the tool has been modified. “The clinical tool for clinicians is intended to support individual conversations with patients about risk. Originally, the goal was to help patients understand the reasons for being asked to shield and, where relevant, help them do so. Since the end of shielding requirements, it is hoped that better-informed conversations about risk will have supported patients to make appropriate decisions about personal risk, either protecting them from adverse health outcomes or to some extent alleviating concerns about re-engaging with society.”
“In essence, the tool creates a risk calculation based on scoring risk factors across a number of data fields pertaining to demographic, clinical and social patient information.“ “The factors incorporated in the model include age, ethnicity, level of deprivation, obesity, whether someone lived in residential care or was homeless, and a range of existing medical conditions, such as cardiovascular disease, diabetes, respiratory disease and cancer. For the latest clinical tool, separate versions of the QCOVID models were estimated for vaccinated and unvaccinated patients.”
It is difficult to assess how intensely the tool is (currently) used, although the ATS indicates that “In the period between 1st January 2022 and 31st March 2022, there were 2,180 completed assessments” and that “Assessment numbers often move with relative infection rate (e.g. higher infection rate leads to more usage of the tool).“ The ATS also stresses that “The use of the tool does not override any clinical decision making but is a supporting device in the decision making process.” “The tool promotes shared decision making with the patient and is an extra point of information to consider in the decision making process. The tool helps with risk/benefit analysis around decisions (e.g. recommendation to shield or take other precautionary measures).”
The impact assessment of this tool is driven by those mandated for medical devices. The description is thus rather technical and not very detailed, although the selected examples it includes do capture the possibility of somebody being misidentified “as meeting the threshold for higher risk”, as well as someone not having “an output generated from the COVID-19 Predictive Risk Model”. The ATS does stress that “As part of patient safety risk assessment, Hazardous scenarios are documented, yet haven’t occurred as suitable mitigation is introduced and implemented to alleviate the risk.” That mitigation largely seems to be that “The tool is designed for use by clinicians who are reminded to look through clinical guidance before using the tool.”
I think this case shows two things. First, that it is difficult to understand how different parts of the analysis fit together when a tool that has had two very different uses is the object of a single ATS disclosure. There seems to be a good argument for use case specific ATS disclosures, even if the underlying AI deployment is the same (or a closely related one), as the implications of different uses from a governance perspective also differ.
Second, that in the context of AI adoption for healthcare purposes, there is a dual barrier to accessing relevant (and understandable) information: the tech barrier and the medical barrier. While the ATS does something to reduce the former, the latter very much remains in place and perhaps turn the issue of trustworthiness of the AI to trustworthiness of the clinician, which is not necessarily entirely helpful (not only in this specific use case, but in many other one can imagine). In that regard, it seems that the usability of the ATS is partially limited, and more could be done to increase meaningful transparency through AI-specific IAs, perhaps as proposed by the Ada Lovelace Institute.
In this case, the ATS disclosure has also provided some valuable information, but arguably to a lesser extent than the previous case study.
ICO’s Registration Inbox AI
This is a tool that very much resembles other forms of email classification (e.g. spam filters), as “This algorithmic tool has been designed to inspect emails sent to the ICO’s registration inbox and send out autoreplies to requests made about changing addresses. The tool has not been designed to automatically change addresses on the requester’s behalf. The tool has not been designed to categorise other types of requests sent to the inbox.”
The disclosure indicates that “In a significant proportion of emails received, a simple redirection to an online service is all that is required. However, sifting these types of emails out would also require time if done by a human. The algorithm helps to sift out some of these types of emails that it can then automatically respond to. This enables greater capacity for [Data Protection] Fees Officers in the registration team, who can, consequently, spend more time on more complex requests.” “There is no manual intervention in the process - the links are provided to the customer in a fully automated manner.”
The tool has been in use since May 2021 and classifies approximately 23,000 emails a month.
When it comes to risk identification and mitigation, the ATS disclosure stresses that “The algorithmic tool does not make any decisions, but instead provides links in instances where it has calculated the customer has contacted the ICO about an address change, giving the customer the opportunity to self-serve.” Moreover, it indicates that there is “No need for review or appeal as no decision is being made. Incorrectly classified emails would receive the default response which is an acknowledgement.” It further stresses that “The classification scope is limited to a change of address and a generic response stating that we have received the customer’s request and that it will be processed within an estimated timeframe. Incorrectly classified emails would receive the default response which is an acknowledgement. This will not have an impact on personal data. Only emails with an 80% certainty of a change of address request will be sent an email containing the link to the change of address form.”
In my view, this disclosure does not entirely clarify the way the algorithm works (e.g. what happens to emails classified as having requested information on change of address? Are they ‘deleted’ from the backlog of emails requiring a (human) non-automated response?). However, it does provide sufficient information to further consolidate the questions arising from the general description. For example, it seems that the identification of risks is clearly partial in that there is not only a risk of someone asking for change of address information not automatically receiving it, but also a risk of those asking for other information receiving the wrong information. There is also no consideration of additional risks (as above), and the general description makes the claim of benefits doubtful if there has to be a manual check to verify adequate classification.
The ATS disclosure does not provide sufficient contact information for the owner of the AI (perhaps because they were contracted on limited after service terms…), although there is generic contact information for the ICO that could be used by someone that considered the situation unsatisfactory or would like to prove it further.
Food Hygiene Rating Scheme – AI
This tool is also based on machine learning to make predictions. “A machine learning framework called LightGBM was used to develop the FHRS AI model. This model was trained on data from three sources: internal Food Standards Agency (FSA) FHRS data, publicly available Census data from the 2011 census and open data from HERE API. Using this data, the model is trained to predict the food hygiene rating of an establishment awaiting its first inspection, as well as predicting whether the establishment is compliant or not.” “Utilising the service, the Environmental Health Officers (EHOs) are provided with the AI predictions, which are supplemented with their knowledge about the businesses in the area, to prioritise inspections and update their inspection plan.”
Regarding the justification for the development, the disclosure stresses that “the number of businesses classified as ‘Awaiting Inspection’ on the Food Hygiene Rating Scheme website has increased steadily since the beginning of the pandemic. This has been the key driver behind the development of the FHRS AI use case.” “The objective is to help local authorities become more efficient in managing the hygiene inspection workload in the post-pandemic environment of constrained resources and rapidly evolving business models.”
Interestingly, the disclosure states that the tool “has not been released to actual end users as yet and hence the maintenance schedule is something that cannot be determined at this point in time (June 2022). The Alpha pilot started at the beginning of April 2022, wherein the end users (the participating Local Authorities) have access to the FHRS AI service for use in their day-to-day workings. This section will be updated depending on the outcomes of the Alpha Pilot ...” It remains to be seen whether there will be future updates on the disclosure, but an error in copy-pasting in the ATS disclosure makes it contain the same paragraph but dated February 2022. This stresses the need to date and reference (eg v.1, v.2) the successive versions of the same disclosure, which does not seem to be a field of the current template, as well as to create a repository of earlier versions of the same disclosure.
The section on oversight stresses that “the system has been designed to provide decision support to Local Authorities. FSA has advised Local Authorities to never use this system in place of the current inspection regime or use it in isolation without further supporting information”. It also stresses that “Since there will be no change to the current inspection process by introducing the model, the existing appeal and review mechanisms will remain in place. Although the model is used for prioritisation purposes, it should not impact how the establishment is assessed during the inspection and therefore any challenges to a food hygiene rating would be made using the existing FHRS appeal mechanism.”
The disclosure also provides detailed information on IAs: “The different impact assessments conducted during the development of the use case were 1. Responsible AI Risk Assessment; 2. Stakeholder Impact Assessment; [and] 3. Privacy Impact Assessment.” Concerning the responsible AI risk assessment, in addition to a personal data issue that should belong in the DPIA, the disclosure reports three identified risks very much in line with the ones I had hinted at above: “2. Potential bias from the model (e.g. consistently scoring establishments of a certain type much lower, less accurate predictions); 3. Potential bias from inspectors seeing predicted food hygiene ratings and whether the system has classified the establishment as compliant or not. This may have an impact on how the organisation is perceived before receiving a full inspection; 4. With the use of AI/ML there is a chance of decision automation bias or automation distrust bias occurring. Essentially, this refers to a user being over or under reliant on the system leading to a degradation of human-reasoning.”
The disclosure presents related mitigation strategies as follows: “2. Integration of explainability and fairness related tooling during exploration and model development. These tools will also be integrated and monitored post-alpha testing to detect and mitigate potential biases from the system once fully operational; 3. Continuously reflect, act and justify sessions with business and technical subject matter experts throughout the delivery of the project, along with the use of the three impact assessments outlined earlier to identify, assess and manage project risks; 4. Development of usage guidance for local authorities specifically outlining how the service is expected to be used. This document also clearly states how the service should not be used, for example, the model outcome must not be the only indicator used when prioritising businesses for inspection.”
In this instance, the ATS disclosure is in itself useful because it allows the type of analysis above and, in case someone considers the situation unsatisfactory or would like to prove it further, there are is a clear gateway to (try to) engage the entity responsible for this AI deployment. It is also interesting to see that the disclosure specifies that the private provider was engaged “As well as [in] a development role [… to provide] Responsible AI consulting and delivery services, including the application of a parallel Responsible AI sprint to assess risk and impact, enable model explainability and assess fairness, using a variety of artefacts, processes and tools”. This is clearly reflected in the ATS disclosure and could be an example of good practice where organisations lack that in-house capability and/or outsource the development of the AI. Whether that role should fall with the developer, or should rather be separate to avoid organisational conflicts of interest is a discussion for another day.
Final thoughts
There seems to be a mixed picture on the usability of the ATS disclosures, with some of them not entirely providing (full) usability, or a clear pathway to engage with the specific entity in charge of the development of the algorithmic tool, specifically if it was an outsourced provider. In those cases, the public authority that has implemented the AI (even if not the owner of the project) will have to deal with any issues arising from the disclosure. There is also a mixed practice concerning linking to resources other than previously available (open) data (eg open source code, data sources), with only one project (GOV.UK) including them in the disclosures discussed above.
It will be interesting to see how this assessment scales up (to use a term) once disclosures increase in volume. There is clearly a research opportunity arising as soon as more ATS disclosures are published. As a hypothesis, I would submit that disclosure quality is likely to reduce with volume, as well as with the withdrawal of whichever support the pilot phase has meant for those participating institutions. Let’s see how that empirical issue can be assessed.
The other reflection I have to offer based on these first four disclosures is that there are points of information in the disclosures that can be useful, at least from an academic (and journalistic?) perspective, to assess the extent to which the public sector has the capabilities it needs to harness digital technologies (more on that soon in this blog).
The four reviewed disclosures show that there was one in-house development (GOV.UK), while the other ones were either procured (QCovid, which disclosure includes a redacted copy of the contract), or contracted out, perhaps even directly awarded (ICO email classifier FSA FHRS - AI). And there are some in between the line indications that some of the implementations may have been relatively randomly developed, unless there was strong pre-existing reliable statistical data (eg on information requests concerning change of business address). Which in itself triggers questions on the procurement or commissioning strategy developed by institutions seeking to harness AI potential.
From this perspective, the ATS disclosures can be a useful source of information on the extent to which the adoption of AI by the public sector depends as strongly on third party capabilities as the literature generally hypothesises or/and is starting to demonstrate empirically.
Is the ESPD the enemy of procurement automation in the EU (quick thoughts)

I have started to watch the three-session series on Intelligent Automation in US Federal Procurement hosted by the GW Law Government Procurement Law Program over the last few weeks (worth watching!), as part of my research for a paper on AI and corruption in procurement. The first session in the series focuses in large part on the intelligent automation of information gathering for the purposes of what in the EU context are the processes of exclusion and qualitative selection of economic providers. And this got me thinking about how it would (or not) be possible to replicate some of the projects in an EU jurisdiction (or even at EU-wide level).
And, once again, the issue of the lack of data on which to train algorithms, as well as the lack of representative/comprehensive databases from which to automatically extract information came up. But somehow it seems like the ESPD and the underlying regulatory approach may be making things more difficult.
In the EU, automating mandatory exclusion (not necessarily to have AI adopt decisions, but to have it prepare reports capable of supporting independent decision-making by contracting authorities) would primarily be a matter of checking against databases of prior criminal convictions, which is not only difficult to do due to the absence of structured databases themselves, but also due to the diversity of legal regimes and the languages involved, as well as the pervasive problem of beneficial ownership and (dis)continuity in corporate personality.
Similarly, for discretionary exclusion, automation would primarily be based on retrieving information concerning grounds not easily or routinely captured in existing databases (eg conflicts of interest), as well as limited by increasingly constraining CJEU case law demanding case-by-case assessments by the contracting authority in ways that diminish the advantages of automating eg red flags based on decisions taken by a different contracting authority (or centralised authority).
Finally, automating qualitative selection would be almost impossible, as it is currently mostly based on the self-certification implicit in the ESPD. Here, the 2014 Public Procurement Directives tried to achieve administrative simplification not through the once only principle (which would be useful in creating databases supporting automatisation of some parts of the project, but on which a 2017 project does not seem to have provided many advances), but rather through the ‘tell us only if successful’ (or suspected) principle. This naturally diminishes the amount of information the public buyer (and the broader public sector) holds, with repeat tenderers being completely invisible for the purposes of automation so long as they are not awarded contracts.
All of this leads me to think that there is a big blind spot in the current EU approach to open procurement data as the solution/enabler of automatisation in the context of EU public procurement practice. In fact, most of the crucial (back office) functions — and especially those relating to probity and quality screenings relating to tenderers — will not be susceptible of automation until (or rather unless) different databases are created and advanced mechanisms of interconnection of national databases are created at EU level. And creating those databases will be difficult (or simply not happen in practice) for as long as the ESPD is in place, unless a parallel system of registration (based on the once only principle) is developed for the purposes of registering onto and using eProcurement platforms (which seems to also raise some issues).
So, all in all, it would seem that more than ever we need to concentrate on the baby step of creating a suitable data architecture if we want to reap the benefits of AI (and robotic process automation in particular) any time soon. As other jurisdictions are starting to move (or crawl, to keep with the metaphor), we should not be wasting our time.
Some thoughts on the Commission's 2021 Report on 'Implementation and best practices of national procurement policies in the Internal Market'

In May 2021, the European Commission published its report on the ‘Implementation and best practices of national procurement policies in the Internal Market’ (the ‘2021 report’). The 2021 report aggregates the national reports sent by Member States in discharge of specific reporting obligations contained in the 2014 Public Procurement Package and offers some insight into the teething issues resulting from its transposition—which may well have become structural issues. In this post, I offer some thoughts on the contents of the 2021 report.
Better late than never?
Before getting to the details of the 2021 report, the first thing to note is the very significant delay in the publication of this information and analysis, as the 2021 report refers to the implementation and practice of procurement covered by the Directives in 2017. The original national reports seem to have been submitted by the Member States (plus Norway, minus Austria for some unexplained reason) in 2018.
Given the limited analysis conducted in the 2021 report, one can wonder why it took the Commission so long. There may be some explanation in the excuses recently put forward to the European Parliament for the continued delay (almost 2 and a half years, and counting) in reporting on the economic effect of the 2014 rules, although that is less than persuasive. Moreover, given that the reporting obligation incumbent on the Member States is triggered every three years, in 2021 we should be having fresh data and analysis of the national reports covering the period 2018-2020 … Oh well, let’s work with what we have.
A missing data (stewardship) nightmare
The 2021 report provides painful evidence of the lack of reliable procurement data in 2017. Nothing new there, sadly—although the detail of the data inconsistencies, including Member States reporting ‘above threshold procurement’ data that differs from what can be extracted from TED (page 4), really should raise a few red flags and prompt a few follow-up questions from the Commission … the open-ended commitment to further investigation (page 4) sounding as too little, too late.
The main issue, though, is that this problem is unlikely to have been solved yet. While there is some promise in the forthcoming implementation of new eForms (to start being used between Nov 2022 and no later than Oct 2023), the broader problem of ensuring uniformity of data collection and (more) timely reporting is likely to remain. It is also surprising to see that the Commission considers that the collection of ‘above threshold’ procurement data is voluntary for Member States (fn 5), when Art 85(1) places them under an obligation to provide ‘missing statistical information’ where it cannot be extracted from (TED) notices.
So, from a governance perspective (and leaving aside the soft, or less, push towards the implementation of OCDS standards in different Member States), it seems that the Commission and the Member States are both happy to just keeping shrugging their shoulders at each other when it comes to the incompleteness and low quality of procurement data. May it be time for the Commission to start enforcing reporting obligations seriously and with adequate follow-ups? Or should we wait to the (2024?) second edition of the implementation report to decide to do something then — although it will then be quite tempting to say that we need to wait and see what effect the (delayed?) adoption of the eForms generates. So maybe in light of the (2027?) third edition of the report?
Lack of capability, and ‘Most frequent sources of wrong application or of legal uncertainty’
The 2021 report includes a section on the reported most frequent sources of incorrect application of the 2014 rules, or perceived areas of legal uncertainty. This section, however, starts with a list of issues that rather point to a shortfall of capabilities in the procurement workforce in (some?) Member States. Again, while the Commission’s work on procurement professionalisation may have slightly changed the picture, this is primarily a matter for Member State investment. And in the current circumstances, it seems difficult to see how the post-pandemic economic recovery funds that are being channeled through procurement can be effectively spent where there are such staffing issues.
The rest of the section includes some selected issues posing concrete interpretation or practical implementation difficulties, such as the calculation of threshold values, the rules on exclusion and the rules on award criteria. While these are areas that will always generate some practical challenges, these are not the areas where the 2014 Package generated most change (certainly not on thresholds) and the 2021 report then seems to keep raising structural issues. The same can be said of the generalised preference for the use of lowest price, the absence of market research and engagement, the imposition of unrealistically short tendering deadlines implicit in rushed procurement, or the arbitrary use of selection criteria.
All of this does not bode well for the ‘strategic use’ of procurement (more below) and it seems like the flexibility and potential for process-based innovation of the 2014 rules (as was that of the 2004 rules?) are likely to remain largely unused, thus triggering poor procurement practices later to fuel further claims for flexibilisation and simplification in the next round of revision. On that note, I cannot refrain from pointing to the UK’s recent green paper on the ‘Transformation of Public Procurement’ as a clear example of the persistence of some procurement myths that remain in the collective imagery despite a lack of engagement with recent legislative changes aimed at debunking them (see here, here, and here for more analysis).
Fraud, corruption, conflict of interest and serious irregularities
The 2021 report then has a section that would seem rather positive and incapable of controversy at first sight, as it presents (laudable) efforts at Member State level to create robust anti-fraud and anti-corruption institutions, as well as implementations of rules on conflict of interest that exceed the EU minimum standard, and the development of sophisticated approaches to the prevention and detection of collusion in procurement. Two comments come to mind here.
The first one is that the treatment of conflicts of interest in the Directive clearly requires the development of further rules at domestic level and that the main issue is not whether the statutes contain suitable definitions, but whether conflicts of interest are effectively screened and (more importantly), reacted to. In that regard, it would be interesting to know, for example, how many decisions finding a non-solvable conflict of interest have led to the exclusion of tenderers at Member State level since the new rules came into force. If anyone wanted to venture an estimate, I would not expect it to be in the 1000s.
The second comment is that the picture that the 2021 report paints about the (2017) development of anti-collusion approaches at Member State level (page 7) puts a large question mark on the need for the recent Notice on tools to fight collusion in public procurement and on guidance on how to apply the related exclusion ground (see comments here). If the Member States were already taking action, why did the (contemporaneous) 2017 Communication on ‘Making public procurement work in and for Europe’ (see here) include a commitment to ‘… develop tools and initiatives addressing this issue and raising awareness to minimise the risks of collusive behaviours on procurement markets. This will include actions to improve the market knowledge of contracting authorities, support to contracting authorities careful planning and design of procurement processes and better cooperation and exchange of information between public procurement and competition authorities. The Commission will also prepare guidelines on the application of the new EU procurement directives on exclusion grounds on collusion.’ Is the Commission perhaps failing to recognise that the 2014 rules, and in particular the new exclusion ground for contemporaneous collusion, created legal uncertainty and complicated the practical application of the emerging domestic practices?
Moreover, the 2021 report includes a relatively secondary comment that the national reports ‘show that developing and applying means for the quantitative assessment of collusion risks in award procedures, mostly in the form of risk indicators, remains a challenge’. This is a big understatement and the absence of (publicly-known?) work by the Commission itself on the development of algorithmic screening for collusion detection purposes can only be explained away by the insufficiency of the existing data (which killed off eg a recent effort in the UK), which brings us back to the importance of stronger data stewardship if some of the structural issues are to be resolved (or started to be resolved) any time soon.
SMEs
There is also little about SME access to procurement in the 2021 report, mainly due to limited data provided in the national reports (so, again, another justification for a tougher approach to data collection and reporting). However, there are a couple of interesting qualitative issues. The first one is that ‘only a limited number of Member States have explicitly mentioned challenges encountered by SMEs in public procurement’ (page 7), which raises some questions about the extent to which SME-centric policy issues rank equally high at EU and at national level (which can be relevant in terms of assessing e.g. the also very recent Report on SME needs in public procurement (Feb 2021, but published July 2021). The second one is that the few national strategies seeking to boost SME participation in procurement concern programmes aimed at increasing interactions between SMEs and contracting authorities at policy and practice design level, as well as training for SMEs. What those programmes have in common is that they require capability and resources to be dedicated to the SME procurement policy. Given the shortcomings evidenced in the 2021 report (above), it should be no wonder that most Member States do not have the resources to afford them.
Green, social & Innovation | ‘strategic procurement’
Not too dissimilarly, the section on the uptake of ‘strategic procurement’ also points at difficulties derived from limited capability or understanding of these issues amongst public buyers, as well as the perception (at least for green procurement) that it can be detrimental to SME participation. There is also repeated reference to lack of clarity of the rules and risks of litigation — both of which are in the end dependent on procurement capability, at least to a large extent.
All of this is particularly important, not only because it reinforces the difficulties of conducting complex or sophisticated procurement procedures that exceed the capability (either in terms of skill or, probably more likely, available time) of the procurement workforce, but also because it once again places some big question marks on the feasibiity of implementing some of the tall asks derived from eg the new green procurement requirements that can be expected to follow from the European Green Deal.
Overal thoughts
All of this leads me to two, not in the least original or groundbreaking, thoughts. First, that procurement data is an enabler of policies and practices (clearly of those supported by digital technologies, but not only) which absence significantly hinders the effectiveness of the procurement function. Second, that there is a systemic and long-lasting underinvestment in procurement capability in (most) Member States — about which there is little the European Commission can do — which also significantly hinders the effectiveness of the procurement function.
So, if the current situation is to be changed, a bold and aggressive plan of investment in an enabling data architecture and legal-commercial (and technical) capability is necessary. Conversely, until (or unless) that happens, all plans to use procurement to prop up or reactivate the economy post-pandemic and, more importantly, to face the challenges of the climate emergency are likely to be of extremely limited practical relevance due to failures in their implementation. The 2021 report clearly supports aggressive action on both fronts (even if it refers to the situation in 2017, the problems are very much still current). Will it be taken?
Open Contracting: Where is the UK and What to Expect?
I had the pleasure of delivering a webinar on ‘Open Contracting Data: Where Are We & What Could We Expect?‘ for the Gloucester branch of the Chartered Institute of Procurement & Supply. The webinar assessed the current state of development and implementation of open contracting data initiatives in the UK. It also considered the main principles and goals of open contracting, as well as its practical implementation, and the specific challenges posed by the disclosure of business sensitive information. The webinar also mapped potential future developments and, more generally, reflected on the relevance of an adequate procurement data infrastructure for the deployment of digital technologies and, in particular, AI. The slides are available (via dropbox) and the recording is also accessible through the image below (as well as via dropbox).
As always, feedback most welcome: a.sanchez-graells@bristol.ac.uk.
PS. For some an update on recent EBRD/EU sponsored open contracting initiatives in Greece and Poland, see here.

3 priorities for policy-makers thinking of AI and machine learning for procurement governance

I find that carrying out research in the digital technologies and governance field can be overwhelming. And that is for an academic currently having the luxury of full-time research leave… so I can only imagine how much more overwhelming it must be for policy-makers thinking about the adoption of artificial intelligence (AI) and machine learning for procurement governance, to identify potential use cases and to establish viable deployment strategies.
Prioritisation seems particularly complicated, as managing such a significant change requires careful planning and paying attention to a wide variety of potential issues. However, getting prioritisation right is probably the best way of increasing the chances of success for the deployment of digital technologies for procurement governance — as well as in other areas of Regtech, such as financial supervision.
This interesting speech by James Proudman (Executive Director of UK Deposit Takers Supervision, Bank of England) on 'Managing Machines: the governance of artificial intelligence', precisely focuses on such issues. And I find the conclusions particularly enlightening:
First, the observation that the introduction of AI/ML poses significant challenges around the proper use of data, suggests that boards should attach priority to the governance of data – what data should be used; how should it be modelled and tested; and whether the outcomes derived from the data are correct.
Second, the observation that the introduction of AI/ML does not eliminate the role of human incentives in delivering good or bad outcomes, but transforms them, implies that boards should continue to focus on the oversight of human incentives and accountabilities within AI/ML-centric systems.
And third, the acceleration in the rate of introduction of AI/ML will create increased execution risks during the transition that need to be overseen. Boards should reflect on the range of skill sets and controls that are required to mitigate these risks both at senior level and throughout the organisation.
These seem to me directly transferable to the context of procurement governance and the design of strategies for the deployment of AI and machine learning, as well as other digital technologies.
First, it is necessary to create an enabling data architecture and to put significant thought into how to extract value from the increasingly available data. In that regard, there are two opportunities that should not be missed. One concerns the treatment of procurement datasets as high-value datasets for the purposes of the special regime of the Open Data Directive (for more details, see section 6 here), which will require careful consideration of the content and level of openness of procurement data in the context of the domestic transpositions that need to be in place by 17 July 2021. The other, related opportunity concerns the implementation of the new rules on eForms for procurement data publications, which Member States need to adopt by 14 November 2022. Building on the data architecture that will result from both sets of changes—which should be coordinated—will allow for the deployment of data analytics and machine learning techniques. The purposes and goals of such deployments also need to be considered carefully, as well as their potential implications.
Second, it seems clear that the changes in the management of procurement data and the quick development of analytics that can support procurement decision-making pile some additional training and upskilling needs on the already existing (and partially unaddressed?) current challenges of full consolidation of eProcurement across the EU. Moreover, it should be clear that there is no such thing as an objective and value neutral implementation of technological governance solutions and that all levels of accountability need to be provided with adequate data skills and digital literacy upgrades in order to check what is being done at the technical level (for crystal-clear discussion, see van der Voort et al, 'Rationality and politics of algorithms. Will the promise of big data survive the dynamics of public decision making?' (2019) 36(1) Government Information Quarterly 27-38). Otherwise, governance mechanism would be at risk of failure due to techno-capture and/or techno-blindness, whether intended or accidental.
Third, there is an increasing need to manage change and the risks that come with it. In a notoriously risk averse policy field such as procurement, this is no minor challenge. This should also prompt some rethinking of the way the procurement function is organised and its risk-management mechanisms.
Addressing these priorities will not be easy or cheap, but these are the fundamental building blocks required to enable the public procurement sector to benefit from the benefits of digital technologies as they mature. In consultancy jargon, these are the priorities to ‘future-proof’ procurement strategies. Will they be adopted?
Postscript
It is worth adding that, in particular the first and second issues, lend themselves to strong collaborations between policy-makers and academics. As rightly pointed out by Pencheva et al, 'Big Data and AI – A transformational shift for government: So, what next for research?' (2018) Public Policy and Administration, advanced access at 16:
... governments should also support the efforts for knowledge creation and analysis by opening up their data further, collaborating with – and actively seeking inputs from – researchers to understand how Big Data can be utilised in the public sector. Ultimately, the supporting field of academic thought will only be as strong as the public administration practice allows it to be.
Oracles as a sub-hype in blockchain discussions, or how my puppy helps me get to 10,000 steps a day

Photo: Rob Alcaraz/The Wall Street Journal.
The more I think about the use of blockchain solutions in the context of public procurement governance—and, more generally, of public services delivery—the more I find that the inability for blockchain technology to reliably connect to the ‘real world’ is bound to restrict any potentially useful applications to back-office functions and the procurement of strictly digital assets.
This is simply because blockchain can only generate its desirable effects of tamper-evident record-keeping and automated execution of smart contracts built on top of it to the extent that it does not require off-chain inputs. Blockchain is also structurally incapable of generating off-chain outputs by itself.
This is increasingly widely-known and is generating a sub-hype around oracles—which are devices aimed at plugging blockchains to the ‘real world’, either by feeding the blockchain with data, or by outputting data from the blockchain (as discussed eg here). In this blog post, I reflect on the minimal changes that I think the development of oracles is likely to have in the context of public procurement governance.
Why would blockchain be interesting in this context?
Generally, the potential for the use of blockchain and blockchain-enabled smart contracts to improve procurement governance is linked to the promise that it can help prevent corruption and mistakes through the automation of decision-making through the procurement process and the execution of public contracts and the immutability (rectius, tamper-evidence) of procurement records. There are two main barriers to the achievement of such improvements over current processes and governance mechanisms. One concerns transactions costs and information asymmetries (as briefly discussed here). The other concerns the massive gap between the virtual on-chain reality and the off-chain real world—which oracles are trying to bridge.
The separation between on-chain and off-chain reality is paramount to the analysis of governance issues and the impact blockchain can have. If blockchain can only displace the focus of potential corrupt or mistaken intervention—by the public buyer, or by public contractors—but not eliminate such risks, its potential contribution to a revolution of procurement governance certainly reduces in various orders of magnitude. So it is important to assess the extent to which blockchain can be complemented with other solutions (oracles) to achieve the elimination of points of entry for corrupt or mistaken activity, rather than their displacement or substitution.
Oracle’s vulnerabilities: my puppy wears my fitbit
In simple terms, oracles are data interfaces that connect a blockchain to a database or a source of data (for a taxonomy and some discussion, see here). This makes them potentially unreliable as (i) the oracle can only be as good as the data it relies on and (ii) the oracle can itself be manipulated. There are thus, two main sources of oracle vulnerability, which automatically translate into blockchain vulnerability.
First, the data can be manipulated—like when I prefer to sit and watch some TV rather than go for a run and tie my fitbit to my puppy’s collar so that, by midnight, I have still achieved my 10,000 daily steps.* Second, the oracle itself can be manipulated because it is a piece of software or hardware that can be tampered with, and perhaps in a way that is not readily evident and which uncovering requires some serious IT forensics—like getting a friend to crack fitbit’s code and add 10,000 daily steps to my database without me even needing to charge my watch.**
Unlilke when these issues concern the extent to which I lie to myself about my healthy lifestyle, these two vulnerabilities are highly problematic from a public governance perspective because, unless the data used in the interaction with the blockchain is itself automatically generated in a way that cannot be manipulated (and this starts to point at a mirror within a mirror situation, see below), the effect of implementing a blockchain plus oracle simply seems to be to displace the governance focus where controls need to be placed towards the source of the data and the devices used to collect it.
But oracles can get better! — sure, but only to deal with data
The sub-hype around oracles in blockchain discussions basically follows the same trend as the main hype around blockchain. The same way it is assumed that blockchain is bound to revolutionise everything because it will get so much better than it currently is, there are emerging arguments about the almost boundless potential for oracles to connect the real world to the blockchain in so much better ways. I do not have the engineering or futurology credentials necessary to pass judgement on this, but it seems to me plain to see that—unless we want to add an additional layer about robotics (and pretty evolved robotics at that), so that we consider blockchain+oracle+robot solutions—any and all advances will remain limited to improving the way data is generated/captured and exploited within and outside the blockchain.
So, for everything that is not data-based or data-transformable (such as the often used example of event tickets, which in the end get plugged back to a database that determines their effects in the real world)—or, in other words, where moving digital tokes around does not generate the necessary effects in the real world—even much advanced blockchain+oracle solutions are likely to remain of limited use in the context of procurement and the delivery of public services. Not because the applications are not (technically) possible, but because they generate governance problems that merely replace the current ones. And the advantage is not necessarily obvious.
How far can we displace governance problems and still reap some advantages?
What do I mean that the advantage is not necessarily obvious? Well, imagine the possibility of having a blockchain+oracle control the inventory of a given consumable, so that the oracle feeds information into the blockchain about the existing level of stock and about new deliveries made by the supplier, so that automated payments are made eg on a per available unit basis. This could be seen as a possible application to avoid the need for different ways of controlling the execution of the contract—or even for the need to procure the consumable in the first place, if a smart contract in the blockchain (the same, or a separate one) is automatically buying them on the basis of a closed system (eg a framework agreement or dynamic purchasing system based on electronic catalogues) or even in the ‘open market’ of the internet. Would this not be advantageous from a governance perspective?
Well, I think it would be a matter of degree because there would still need to be a way of ensuring that the oracle is not tampered with and that what the oracle is capturing reflects reality. There are myriad ways in which you could manipulate most systems—and, given the right economic incentives, there will always be attempts to manipulate even the most sophisticated systems we may want to put in place—so checks will always be needed. At this stage, the issue becomes one of comparing the running costs of the system. Unless the cost of the blockchain+oracle+new checks (plus the cybersecurity needed to keep them up and properly running) is lower than the cost of existing systems (including inefficiencies derived from corruption and mistakes), there is no obvious advantage and likely no public interest in the implementation of solutions based on these disruptive technologies.
Which leads me to the new governance issue that has started to worry me: the control of ‘business cases’ for the implementation of blockchain-based solutions in the context of public procurement (and public governance more generally). Given the lack of data and the difficulty in estimating some of the risks and costs of both the existing systems and any proposed new blockchain solutions, who is doing the math and on the basis of what? I guess convincingly answering this will require some more research, but I certainly have a hunch that not much robust analysis is going on…
_____
* I do not have a puppy, though, so I really end up doing my own running…
** I am not sure this is technically doable, but hopefully it works for the sake of the example…
Further thoughts on data and policy indicators a-propos two recent papers on procurement regulation & competition: comments re (Tas: 2019a&b)
The EUI Robert Schuman Centre for Advanced Studies’ working papers series has two interesting recent additions on the economic analysis of procurement regulation and its effects on competition, efficiency and value for money. Both papers are by BKO Tas.
The first paper: ‘Bunching Below Thresholds to Manipulate Public Procurement’ explores the effects of a contracting authority’s ‘bunching strategy’ to seek to exercise more discretion by artificially estimating the value of future contracts just below the thresholds that would trigger compliance with EU procurement rules. This paper is relevant to the broader discussion on the usefulness and adequacy of current EU (and WTO GPA) value thresholds (see eg the work of Telles, here and here), as well as on the regulatory decisions that EU Member States face on whether to extend the EU rules to ‘below-threshold’ contracts.
The second paper: ‘Effect of Public Procurement Regulation on Competition and Cost-Effectiveness’ uses the World Bank’s ‘Benchmarking Public Procurement’ quality scores to empirically test the positive effects of improved regulation quality on competition and value for money, measured as increases in the number of bidders and the probability that procurement price is lower than estimated cost. This paper is relevant in the context of recent discussions about the usefulness or not of procurement benchmarks, and regarding the increasing concern about reduced number of bids in EU-regulated public tenders.
In this blog post, I reflect on the methodology and insights of both papers, paying particular attention to the fact that both papers build on datasets and/or indexes (TED, the WB benchmark) that I find rather imperfect and unsuitable for this type of analysis (regarding TED, in the context of the Single Market Scoreboard for Public Procurement (SMPP) that builds upon it, see here; regarding the WB benchmark, see here). Therefore, not all criticisms below are to the papers themselves, but rather to the distortions that skewed, incomplete or misleading data and indicators can have on more refined analysis that builds upon them.
Bunching Below Thresholds to Manipulate Procurement (Tas: 2019a)
It is well-known that the EU procurement rules are based on a series of jurisdictional triggers and that one of them concerns value thresholds—currently regulated in Arts 4 & 5 of Directive 2014/24/EU. Contracts with an estimated value above those thresholds are subjected to the entire EU procurement regulation, whereas contracts of a lower value are solely subjected to principles-based requirements where they are of ‘cross-border interest’. Given the obvious temptation/interest in keeping procurement shielded from EU requirements, the EU Directives have included an anti-circumvention rule aimed at preventing Member States from artificially splitting contracts in order to keep their award below the relevant jurisdictional thresholds (Art 5(3) Dir 2014/24). This rule has been interpreted expansively by the Court of Justice of the European Union (see eg here).
‘Bunching Below Thresholds to Manipulate Public Procurement’ examines the effects of a practice that would likely infringe the anti-circumvention rule, as it assesses a strategy of ‘bunching estimated costs just below thresholds’ ‘to exercise more discretion in public procurement’. The paper develops a methodology to identify contracting authorities ‘that have higher probabilities of bunching estimated values below EU thresholds’ (ie manipulative authorities) and finds that ‘[m]anipulative authorities have significantly lower probabilities of employing competitive procurement procedure. The bunching manipulation scheme significantly diminishes cost-effectiveness of public procurement. On average, prices of below threshold contracts are 18-28% higher when the authority has an elevated probability of bunching.’ These are quite striking (but perhaps not surprising) results.
The paper employs a regression discontinuity approach to determine the likelihood of bunching. In order to do that, the paper relies on the TED database. The paper is certainly difficult to read and hardly intelligible for a lawyer, but there are some issues that raise important questions. One concerns the authors’ (mis)understanding of how the WTO GPA and the EU procurement rules operate, in particular when the paper states that ‘Contracts covered by the WTO GPA are subject to additional scrutiny by international organizations and authorities (sic). Accordingly, contracts covered by the WTO GPA are less likely to be manipulated by EU authorities’ (p. 12). This is simply an acritical transplant of considerations made by the authors of a paper that examined procurement in the Czech Republic, where the relevant threshold between EU covered and non-EU covered procurement would make sense. Here, the distinction between WTO GPA and EU-covered procurement simply makes no sense, given that WTO GPA and EU thresholds are coordinated. This alone raises some issues concerning the tests designed by the author to check the robustness of the hypothesis that bunching leads to inefficiency in procurement expenditure.
Another issue concerns the way in which the author equates open procedures to a ‘first price auction mechanism’ (which they are not exactly) and dismisses other procedures (notably, the restricted procedure) as incapable of ensuring value for money or, more likely, as representative of a higher degree of discretion for the contracting authority—which is a highly questionable assumption.
More importantly, I am not sure that the author understood what is in the TED database and, crucially, what is not there (see section 2 of Tas (2019a) for methodology and data description). Albeit not very clearly, the author presents TED as a comprehensive database of procurement notices—ie, as if 100% of procurement expenditure by Member States was recorded there. However, in the specific context of bunching below thresholds, the TED database is very likely to be incomplete.
Contracting authorities tendering contracts below EU thresholds are under no obligation to publish a contract notice (Art 49 Dir 2014/24). They could publish voluntarily, in particular in the form of a voluntary ex ante transparency (VEAT) notice, but that would make no sense from the perspective of a contracting authority that seeks to avoid compliance with EU rules by bunching (ie manipulating) the estimated contract value, as that would expose it to potential litigation. Most authorities that are bunching their procurement needs (or, in simple terms) avoiding compliance with the EU rules will not be reflected in the TED database at all, or will not be identified by the methodology used by Tas (2019a), as they will not have filed any notices for contracts below thresholds.
How is it possible that TED includes notices regarding contracts below the EU thresholds, then? Well, this is anybody’s guess, but mine is that a large proportion of those notices will be linked to either countries with a tradition of full transparency (over-reporting), to contracts where there are any doubts about the potential cross-border interest (sometimes assessed over-cautiously), or will be notices with mistakes, where the estimated value of the contract is erroneously indicated as below thresholds.
Even if my guess was incorrect and all notices for contracts with a value below thresholds were accurate and justified by the existence of a potential cross-border interest, the database cannot be considered complete. One of the issues raised (imperfectly) by the Single Market Scoreboard (indicator [3] publication rate) is the relatively low level of procurement that is advertised in TED compared to the (putative/presumptive) total volume of procurement expenditure by the Member States. Without information on the conditions of the vast majority of contract awards (below thresholds, unreported, etc), any analysis of potential losses of competitiveness / efficiency in public expenditure (due to bunching or otherwise) is bound to be misleading.
Moreover, Tas (2019a) is premised on the hypothesis that procurement below EU thresholds allows for significantly more discretion than procurement above those thresholds. However, this hypothesis fails to recognise the variety of transposition strategies at Member State level. While some countries have opted for less stringent below EU threshold regimes, others have extended the EU rules to the entirety of their procurement (or, perhaps, to contracts up to and including much lower values than the EU thresholds, to the exception of some class of ‘micropurchases’). This would require the introduction of a control that could refine Tas’ analysis and distinguish those cases of bunching that do lead to more discretion and those that do not (at least formally)—which could perhaps distinguish between price effects derived from national-only transparency from those of more legally-dubious maneuvering.
In my view, regardless of the methodology and the math underpinning the paper (which I am in no position to assess in detail), once these data issues are taken into account, the story the paper tries to tell breaks down and there are important shortcomings in its empirical strategy that, in my view, raise significant issues around the strength of its findings—assessed not against the information in TED, but against the (largely unknown, unrecorded) reality of procurement in the EU.
I have no doubt that there is bunching in practice, and that the intuition that it raises procurement costs must be right, but I have serious doubts about the possibility to reliably identify bunching or estimate its effects on the basis of the information in TED, as most culprits will not be included and the effects of below threshold (national) competition only will mostly not be accounted for.
(Good) Regulation, Competition & Cost-Effectiveness (Tas: 2019b)
It is also a very intuitive hypothesis that better regulation should lead to better procurement outcomes and, consequently, that more open and robust procurement rules should lead to more efficiency in the expenditure of public funds. As mentioned above, Tas (2019b) explores this hypothesis and seeks to empirically test it using the TED database and the World Bank’s Benchmarking Public Procurement (in its 2017 iteration, see here). I will not repeat my misgivings about the use of the TED database as a reliable source of information. In this second part, I will solely comment on the use of the WB’s benchmark.
The paper relies on four of the WB’s benchmark indicators (one further constructed by Djankov et al (2017)): the ‘bid preparation score, bid and contract management score, payment of suppliers score and PP overall index’. The paper includes a useful table with these values (see Tas (2019b: Table 4)), which allows the author to rank the countries according to the quality of their procurement regulation. The findings of Tas (2019b) are thus entirely dependent on the quality of the WB’s benchmark and its ability to capture (and distinguish) good procurement regulation.
In order to test the extent to which the WB’s benchmark is a good input for this sort of analysis, I have compared it to the indicator that results from the European Commission’s Single Market Scoreboard for Public Procurement (SMSPP, in its 2018 iteration). The comparison is rather striking …

Source: own elaboration.
Clearly, both sets of indicators are based on different methodologies and measure relatively different things. However, they are both intended to express relevant regulators’ views on what constitutes ‘good procurement regulation’. In my view, both of them fail to do so for reasons already given (see here and here).
The implications for work such as Tas (2019b) is that the reliability of the findings—regardless of the math underpinning them—is as weak as the indicators they are based on. Likely, plugging the same methods to the SMSPP instead of the WB’s index would yield very different results—perhaps, that countries with very low quality of procurement regulation (as per the SMSPP index) achieve better economic results, which would not be a popular story with policy-makers… and the results with either index would also be different if the algorithms were not fed by TED, but by a more comprehensive and reliable database.
So, the most that can be said is that attempts to empirically show effects of good (or poor) procurement regulation remain doomed to fail or , in perhaps less harsh terms, doomed to tell a story based on a very skewed, narrow and anecdotal understanding of procurement and an incomplete recording of procurement activity. Believe those stories at your own peril…
Data and procurement policy: some thoughts on the Single Market Scoreboard for public procurement
There is a growing interest in the use of big data to improve public procurement performance and to strengthen procurement governance. This is a worthy endeavour and, like many others, I am concentrating my research efforts in this area. I have not been doing this for too long. However, soon after one starts researching the topic, a preliminary conclusion clearly emerges: without good data, there is not much that can be done. No data, no fun. So far so good.
It is thus a little discouraging to confirm that, as is widely accepted, there is no good data architecture underpinning public procurement practice and policy in the EU (and elsewhere). Consequently, there is a rather limited prospect of any real implementation of big data-based solutions, unless and until there is a significant investment in the creation of a proper data foundation that can enable advanced analysis and policy-making. Adopting the Open Contracting Data Standard for the European Union would be a good place to start. We could then discuss to what extent the data needs to be fully open (hint: it should not be, see here and here), but let’s save that discussion for another day.
What a recent twitter threat has reminded me is that there is a bigger downside to the existence of poor data than being unable to apply advanced big data analytics: the formulation of procurement policy on the basis of poor data and poor(er) statistical analysis.
This reflection emerged on the basis of the 2018 iteration of the Single Market Scoreboard for Public Procurement (the SMSPP), which is the closest the European Commission is getting to data-driven policy analysis, as far as I can see. The SMSPP is still work in progress. As such, it requires some close scrutiny and, in my view, strong criticism. As I will develop in the rest of this post, the SMSPP is problematic not solely in the way it presents information—which is clearly laden by implicit policy judgements of the European Commission—but, more importantly, due to its inability to inform either cross-sectional (ie comparative) or time series (ie trend) analysis of public procurement policy in the single market. Before developing these criticisms, I will provide a short description of the SMSPP (as I understand it).
The Single Market Scoreboard for Public Procurement: what is it?
The European Commission has developed the broader Single Market Scoreboard (SMS) as an instrument to support its effort of monitoring compliance with internal market law. The Commission itself explains that the “scoreboard aims to give an overview of the practical management of the Single Market. The scoreboard covers all those areas of the Single Market where sufficient reliable data are available. Certain areas of the Single Market such as financial services, transport, energy, digital economy and others are closely monitored separately by the responsible Commission services“ (emphasis added). The SMS organises information in different ways, such as by stage in the governance cycle; by performance per Member State; by governance tool; by policy area or by state of trade integration and market openness (the latter two are still work in progress).
The SMS for public procurement (SMSPP) is an instance of SMS by policy area. It thus represents the Commission’s view that the SMSPP is (a) based on sufficiently reliable data, as it is fed from the database resulting from the mandatory publications of procurement notices in the Tenders Electronic Daily (TED), and (b) a useful tool to provide an overview of the functioning of the single market for public procurement or, in other words of the ‘performance’ of public procurement, defined as a measure of ‘whether purchasers get good value for money‘.
The SMSPP determines the overall performance of a given Member States by aggregating a number of indicators. Currently, the SMSPP is based on 12 indicators (it used to be based on a smaller number, as discussed below): [1] Single bidder; [2] No calls for bids; [3] Publication rate; [4] Cooperative procurement; [5] Award criteria; [6] Decision speed; [7] SME contractors; [8] SME bids; [9] Procedures divided into lots; [10] Missing calls for bids; [11] Missing seller registration numbers; [12] Missing buyer registration numbers. As the SMSPP explains, the addition of these indicators results in the measure of ‘overall performance’, which
is a sum of scores for all 12 individual indicators (by default, a satisfactory performance in an individual indicator increases the overall score by one point while an unsatisfactory performance reduces it by one point). The 3 most important are triple-weighted (Single bidder, No calls for bids and Publication rate). This is because they are linked with competition, transparency and market access–the core principles of good public procurement. Indicators 7-12 receive a one-third weighting. This is because they measure the same concepts from different perspectives: participation by small firms (indicators 7-9) and data quality (indicators 10-12).
The most recent snapshot of overall procurement performance is represented in the map below, which would indicate that procurement policy is rather disfunctional—as most EEA countries do not seem to be doing very well.

Source: European Commission, 2018 Single Market Scorecard for Public Procurement (based on 2017 data).
In my view, this use of the available information is very problematic: (a) to begin with, because the data in TED can hardly be considered ‘sufficiently reliable‘. The database in TED has problems of various sorts because it is a database that is constructed as a result of the self-declaration of data by the contracting authorities of the Member States, which makes its content very dishomogeneous and difficult to analyse, including significant problems of under-inclusiveness, definitional fuzziness and the lack of filtering of errors—as recognised, repeatedly, in the methodology underpinning the SMSPP itself. This should make one take the results of the SMSPP with more than a pinch of salt. However, these are not all the problems implicit in the SMSPP.
More importantly: (b) the definition of procurement performance and the ways in which the SMSPP seeks to assess it are far from universally accepted. They are rather judgement-laden and reflect the policy biases of the European Commission without making this sufficiently explicit. This issue requires further elaboration.
The SMSPP as an expression of policy-making: more than dubious judgements
I already criticised the Single Market Scoreboard for public procurement three years ago, mainly on the basis that some of the thresholds adopted by the European Commission to establish whether countries performed well or poorly in relation to a given indicator were not properly justified or backed by empirical evidence. Unfortunately, this remains the case and the Commission is yet to make a persuasive case for its decision that eg, in relation to indicator [4] Cooperative procurement, countries that aggregate 10% or more of their procurement achieve good procurement performance, while countries that aggregate less than 10% do not.
Similar issues arise with other indicators, such as [3] Publication rate, which measures the value of procurement advertised on TED as a proportion of national Gross Domestic Product (GDP). It is given threshold values of more than 5% for good performance and less than 2.5% for poor performance. The Commission considers that this indicator is useful because ‘A higher score is better, as it allows more companiesto bid, bringing better value for money. It also means greater transparency, as more information is available to the public.’ However, this is inconsistent with the fact that the SMSPP methodology stresses that it is affected by the ‘main shortcoming … that it does not reflect the different weight that government spending has in the economy of a particular’ Member State (p. 13). It also fails to account for different economic models where some Member States can retain a much larger in-house capability than others, as well as failing to reflect other issues such as fiscal policies, etc. Moreover, the SMSPP includes a note that says that ‘Due to delays in data availability, these results are based on 2015 data (also used in the 2016 scoreboard). However, given the slow changes to this indicator, 2015 results are still relevant.‘ I wonder how is it possible to establishes that there are ‘slow changes’ to the indicator where there is no more current information. On the whole, this is clearly an indicator that should be dropped, rather than included with such a phenomenal number of (partially hidden) caveats.
On the whole, then, the SMSPP and a number of the indicators on which it is based is reflective of the implicit policy biases of the European Commission. In my view, it is disingenuous to try to save this by simply stressing that the SMSPP and its indicators
Like all indicators, however, they simplify reality. They are affected by country-specific factors such as what is actually being bought, the structure of the economies concerned, and the relationships between different tendering options, none of which are taken into account. Also, some aspects of public procurement have been omitted entirely or covered only indirectly, e.g. corruption, the administrative burden and professionalism. So, although the Scoreboard provides useful information, it gives only a partial view of EU countries' public procurement performance.
I would rather argue that, in these conditions, the SMSPP is not really useful. In particular, because it fails to enable analysis that could offer some valuable insights even despite the shortcomings of the underlying indicators: first, a cross-sectional analysis by comparing different countries under a single indicator; second, a trend analysis of evolution of procurement “performance” in the single market and/or in a given country.
The SMSPP and cross-sectional analysis: not fit for purpose
This criticism is largely implicit in the previous discussion, as the creation of indicators that are not reflective of ‘country-specific factors such as what is actually being bought, the structure of the economies concerned, and the relationships between different tendering options’ by itself prevents meaningful comparisons across the single market. Moreover, a closer look at the SMSPP methodology reveals that there are further issues that make such cross-sectional analysis difficult. To continue the discussion concerning indicator [4] Cooperative procurement, it is remarkable that the SMSPP methodology indicates that
[In previous versions] the only information on cooperative procurement was a tick box indicating that "The contracting authority is purchasing on behalf of other contracting authorities". This was intended to mean procurement in one of two cases: "The contract is awarded by a central purchasing body" and "The contract involves joint procurement". This has been made explicit in the [current methodology], where these two options are listed instead of the option on joint procurement. However, as always, there are exceptions to how uniformly this definition has been accepted across the EU. Anecdotally, in Belgium, this field has been interpreted as meaning that the management of the procurement procedure has been outsource[d] (e.g. to a legal company) -which explains the high values of this indicator for Belgium.
In simple terms, what this means is that the data point for Belgium (and any other country?) should have been excluded from analysis. In contrast, the SMSPP presents Belgium as achieving a good performance under this indicator—which, in turn, skews the overall performance of the country (which is, by the way, one of the few achieving positive overall performance… perhaps due to these data issues?).
This should give us some pause before we decide to give any meaning to cross-country comparisons at all. Additionally, as discussed below, we cannot (simply) rely on year-on-year comparisons of the overall performance of any given country.
The SMSPP and time series analysis: not fit for purpose
Below is a comparison of the ‘overall performance’ maps published in the last five iterations of the SMSPP.

Source: own elaboration, based on the European Commission’s Single Market Scoreboard for Public Procurement for the years 2014-2018 (please note that this refers to publication years, whereas the data on which each of the reports is based corresponds to the previous year).
One would be tempted to read these maps as representing a time series and thus as allowing for trend analysis. However, that is not the case, for various reasons. First, the overall performance indicator has been constructed on the basis of different (sub)indicators in different iterations of the SMSPP:
the 2014 iteration was based on three indicators: bidder participation; accessibility and efficiency.
the 2015 SMSPP included six indicators: single bidder; no calls for bids; publication rate; cooperative procurement; award criteria and decision speed.
the 2016 SMSPP also included six indicators. However, compared to 2015, the 2016 SMSPP omitted ‘publication rate’ and instead added an indicator on ‘reporting problems’.
the 2017 SMSPP expanded to 9 indicators. Compared to 2016, the 2017 SMSPP reintroduced ‘publication rate’ and replaced ‘reporting problems’ for indicators on ‘missing values’, ‘missing calls for bids’ and ‘missing registration numbers’.
the 2018 SMSPP, as mentioned above, is based on 12 indicators. Compared to 2017, the 2018 SMSPP has added indicators on ‘SME contractors’, ‘SME bids’ and ‘procedures divided into lots’. It has also deleted the indicator ‘missing values’ and disaggregated the ‘missing registration numbers’ into ‘missing seller registration numbers’ and ‘missing buyer registration numbers’.
It is plain that there are no two consecutive iterations of the SMSPP based on comparable indicators. Moreover, the way that the overall performance is determined has also changed. While the SMSPP for 2014 to 2017 established the overall performance as a ‘deviation from the average’ of sorts, whereby countries were given ‘green’ for overall marks above 90% of the average mark, ‘yellow’ for overall marks between 80 and 90% of the average mark, and ‘red’ for marks below 80% of the average mark; in the 2018 SMSPP, ‘green’ indicates a score above 3, ‘yellow’ indicates a score below 3 and above -3, and ‘red’ indicates a score below -3. In other words, the colour coding for the maps has changed from a measure of relative performance to a measure of absolute performance—which, in fairness, could be more meaningful.
As a result of these (and, potentially, other) issues, the SMSPP is clearly unable to support trend analysis, either at single market or country level. However, despite the disclaimers in the published documents, this remains a risk (to the extent that anyone really engages with the SMSPP).
Overall conclusion
The example of the SMSPP does not augur very well for the adoption of data analytics-based policy-making. This is a case where, despite acknowledging shortcomings in the methodology and the data, the Commission has pressed on, seemingly on the premise that ‘some data (analysis) is better than none’. However, in my view, this is the wrong approach. To put it plainly, the SMSPP is rather useless. However, it may create the impression that procurement data is being used to design policy and support its implementation. It would be better for the Commission to stop publishing the SMSPP until the underlying data issues are corrected and the methodology is streamlined. Otherwise, the Commission is simply creating noise around data-based analysis of procurement policy, and this can only erode its reputation as a policy-making body and the guardian of the single market.
US GAO reports on test commercial items program for #publicprocurement
 In a recently published report, the US Government Accountability Office (GAO) assessed the status of a test program for the acquisition of commercial items and services--i.e. are those that generally available in the commercial marketplace in contrast with items developed to meet specific governmental requirements.
In a recently published report, the US Government Accountability Office (GAO) assessed the status of a test program for the acquisition of commercial items and services--i.e. are those that generally available in the commercial marketplace in contrast with items developed to meet specific governmental requirements.
The report is interesting, and it highlights that US federal agencies are conducting around 2% of their procurement through this program and that, overall, the "test program reduced contracting lead time and administrative burdens and generally did not incur additional risks above those on other federal acquisition efforts for those contracts GAO reviewed." Therefore, there seems to be scope for further use of the commercial items acquisition program.
Importantly too, GAO warns that, however, a significant number of these contracts were "awarded noncompetitively [and that, w]hile these awards were justified and approved in accordance with federal regulations when required, GAO and others have found that noncompetitive contracting poses risks of not getting the best value because these awards lack a direct market mechanism to help establish pricing." Consequently, GAO has recommended the interested federal agencies to look in more detail into the use of the program and to take measures to ensure that thorough market research is conducted before a commercial items contract is awarded noncompetitively.
 In my view, the emphasis that GAO places on the collection and analysis of data in order to determine the benefits and success of the commercial items program offers valuable insights to procurement regulators in other jurisdictions--and, particularly, in the EU, where Member States should start considering procurement reform in view of the imminent publication of the new Directives in the Official Journal.
In my view, the emphasis that GAO places on the collection and analysis of data in order to determine the benefits and success of the commercial items program offers valuable insights to procurement regulators in other jurisdictions--and, particularly, in the EU, where Member States should start considering procurement reform in view of the imminent publication of the new Directives in the Official Journal.