Now that my research project ‘Digital technologies and public procurement. Gatekeeping and experimentation in digital public governance’ nears its end, some outputs start to emerge. In this post, I would like to highlight two policy briefings summarising some of my top-level policy recommendations, and providing links to more detailed analysis. All materials are available in the ‘Digital Procurement Governance’ tab.


Two roles of procurement in public sector digitalisation: gatekeeping and experimentation

In a new draft chapter for my monograph, I explore how, within the broader process of public sector digitalisation, and embroiled in the general ‘race for AI’ and ‘race for AI regulation’, public procurement has two roles. In this post, I summarise the main arguments (all sources, included for quoted materials, are available in the draft chapter).
This chapter frames the analysis in the rest of the book and will be fundamental in the review of the other drafts, so comments would be most welcome (a.sanchez-graells@bristol.ac.uk).
Public sector digitalisation is accelerating in a regulatory vacuum
Around the world, the public sector is quickly adopting digital technologies in virtually every area of its activity, including the delivery of public services. States are not solely seeking to digitalise their public sector and public services with a view to enhance their operation (internal goal), but are also increasingly willing to use the public sector and the construction of public infrastructure as sources of funding and spaces for digital experimentation, to promote broader technological development and boost national industries in a new wave of (digital) industrial policy (external goal). For example, the European Commission clearly seeks to make the ‘public sector a trailblazer for using AI’. This mirrors similar strategic efforts around the globe. The process of public sector digitalisation is thus embroiled in the broader race for AI.
Despite the fact that such dynamic of public sector digitalisation raises significant regulatory risks and challenges, well-known problems in managing uncertainty in technology regulation—ie the Collingridge dilemma or pacing problem (‘cannot effectively regulate early on, so will probably regulate too late’)—and different normative positions, interact with industrial policy considerations to create regulatory hesitation and side-line anticipatory approaches. This creates a regulatory gap —or rather a laissez faire environment—whereby the public sector is allowed to experiment with the adoption of digital technologies without clear checks and balances. The current strategy is by and large one of ‘experiment first, regulate later’. And while there is little to no regulation, there is significant experimentation and digital technology adoption by the public sector.
Despite the emergence of a ‘race for AI regulation’, there are very few attempts to regulate AI use in the public sector—with the EU’s proposed EU AI Act offering a (partial) exception—and general mechanisms (such as judicial review) are proving slow to adapt. The regulatory gap is thus likely to remain, at least partially, in the foreseeable future—not least, as the effective functioning of new rules such as the EU AI Act will not be immediate.
Procurement emerges as a regulatory gatekeeper to plug that gap
In this context, proposals have started to emerge to use public procurement as a tool of digital regulation. Or, in other words, to use the acquisition of digital technologies by the public sector as a gateway to the ‘regulation by contract’ of their use and governance. Think tanks, NGOs, and academics alike have stressed that the ‘rules governing the acquisition of algorithmic systems by governments and public agencies are an important point of intervention in ensuring their accountable use’, and that procurement ‘is a central policy tool governments can deploy to catalyse innovation and influence the development of solutions aligned with government policy and society’s underlying values’. Public procurement is thus increasingly expected to play a crucial gatekeeping role in the adoption of digital technologies for public governance and the delivery of public services.
Procurement is thus seen as a mechanism of ‘regulation by contract’ whereby the public buyer can impose requirements seeking to achieve broad goals of digital regulation, such as transparency, trustworthiness, or explainability, or to operationalise more general ‘AI ethics’ frameworks. In more detail, the Council of Europe has recommended using procurement to: (i) embed requirements of data governance to avoid violations of human rights norms and discrimination stemming from faulty datasets used in the design, development, or ongoing deployment of algorithmic systems; (ii) ‘ensure that algorithmic design, development and ongoing deployment processes incorporate safety, privacy, data protection and security safeguards by design’; (iii) require ‘public, consultative and independent evaluations of the lawfulness and legitimacy of the goal that the [procured algorithmic] system intends to achieve or optimise, and its possible effects in respect of human rights’; (iv) require the conduct of human rights impact assessments; or (v) promote transparency of the ‘use, design and basic processing criteria and methods of algorithmic systems’.
Given the absence of generally applicable mandatory requirements in the development and use of digital technologies by the public sector in relation to some or all of the stated regulatory goals, the gatekeeping role of procurement in digital ‘regulation by contract’ would mostly involve the creation of such self-standing obligations—or at least the enforcement of emerging non-binding norms, such as those developed by (voluntary) standardisation bodies or, more generally, by the technology industry. In addition to creating risks of regulatory capture and commercial determination, this approach may overshadow the difficulties in using procurement for the delivery of the expected regulatory goals. A closer look at some selected putative goals of digital regulation by contract sheds light on the issue.
Procurement is not at all suited to deliver incommensurable goals of digital regulation
Some of the putative goals of digital regulation by contract are incommensurable. This is the case in particular of ‘trustworthiness’ or ‘responsibility’ in AI use in the public sector. Trustworthiness or responsibility in the adoption of AI can have several meanings, and defining what is ‘trustworthy AI’ or ‘responsible AI’ is in itself contested. This creates a risk of imprecision or generality, which could turn ‘trustworthiness’ or ‘responsibility’ into mere buzzwords—as well as exacerbate the problem of AI ethics-washing. As the EU approach to ‘trustworthy AI’ evidences, the overarching goals need to be broken down to be made operational. In the EU case, ‘trustworthiness’ is intended to cover three requirements for lawful, ethical, and robust AI. And each of them break down into more detailed or operationalizable requirements.
In turn, some of the goals into which ‘trustworthiness’ or ‘responsibility’ breaks down are also incommensurable. This is notably the case of ‘explainability’ or interpretability. There is no such thing as ‘the explanation’ that is required in relation to an algorithmic system, as explanations are (technically and legally) meant to serve different purposes and consequently, the design of the explainability of an AI deployment needs to take into account factors such as the timing of the explanation, its (primary) audience, the level of granularity (eg general or model level, group-based, or individual explanations), or the level of risk generated by the use of the technical solution. Moreover, there are different (and emerging) approaches to AI explainability, and their suitability may well be contingent upon the specific intended use or function of the explanation. And there are attributes or properties influencing the interpretability of a model (eg clarity) for which there are no evaluation metrics (yet?). Similar issues arise with other putative goals, such as the implementation of a principle of AI minimisation in the public sector.
Given the way procurement works, it is ill-suited for the delivery of incommensurable goals of digital regulation.
Procurement is not well suited to deliver other goals of digital regulation
There are other goals of digital regulation by contract that are seemingly better suited to delivery through procurement, such as those relating to ‘technical’ characteristics such as neutrality, interoperability, openness, or cyber security, or in relation to procurement-adjacent algorithmic transparency. However, the operationalisation of such requirements in a procurement context will be dependent on a range of considerations, such as judgements on the need to keep information confidential, judgements on the state of the art or what constitutes a proportionate and economically justified requirement, the generation of systemic effects that are hard to evaluate within the limits of a procurement procedure, or trade-offs between competing considerations. The extent to which procurement will be able to operationalise the desired goals of digital regulation will depend on its institutional embeddedness and on the suitability of procurement tools to impose specific regulatory approaches. Additional analysis conducted elsewhere (see here and here) suggests that, also in relation to these regulatory goals, the emerging approach to AI ‘regulation by contract’ cannot work well.
Procurement digitalisation offers a valuable case study
The theoretical analysis of the use of procurement as a tool of digital ‘regulation by contract’ (above) can be enriched and further developed with an in-depth case study of its practical operation in a discrete area of public sector digitalisation. To that effect, it is important to identify an area of public sector digitalisation which is primarily or solely left to ‘regulation by contract’ through procurement—to isolate it from the interaction with other tools of digital regulation (such as data protection, or sectoral regulation). It is also important for the chosen area to demonstrate a sufficient level of experimentation with digitalisation, so that the analysis is not a mere concretisation of theoretical arguments but rather grounded on empirical insights.
Public procurement is itself an area of public sector activity susceptible to digitalisation. The adoption of digital tools is seen as a potential source of improvement and efficiency in the expenditure of public funds through procurement, especially through the adoption of digital technology solutions developed in the context of supply chain management and other business operations in the private sector (or ‘ProcureTech’), but also through the adoption of digital tools tailored to the specific goals of procurement regulation, such as the prevention of corruption or collusion. There is emerging evidence of experimentation in procurement digitalisation, which is shedding light on regulatory risks and challenges.
In view of its strategic importance and the current pace of procurement digitalisation, it is submitted that procurement is an appropriate site of public sector experimentation in which to explore the shortcomings of the approach to AI ‘regulation by contract’. Procurement is an adequate case study because, being a ‘back-office’ function, it does not concern (likely) high-risk uses of AI or other digital technologies, and it is an area where data protection regulation is unlikely to provide a comprehensive regulatory framework (eg for decision automation) because the primary interactions are between public buyers and corporate institutions.
Procurement therefore currently represents an unregulated digitalisation space in which to test and further explore the effectiveness of the ‘regulation by contract’ approach to governing the transition to a new model of digital public governance.
* * * * * *
The full draft is available on SSRN as: Albert Sanchez-Graells, ‘The two roles of procurement in the transition towards digital public governance: procurement as regulatory gatekeeper and as site for public sector experimentation’ (March 10, 2023): https://ssrn.com/abstract=4384037.
Procurement centralisation, digital technologies and competition (new working paper)

Source: Wikipedia.
I have just uploaded on SSRN the new working paper ‘Competition Implications of Procurement Digitalisation and the Procurement of Digital Technologies by Central Purchasing Bodies’, which I will present at the conference on “Centralization and new trends" to be held at the University of Copenhagen on 25-26 April 2023 (there is still time to register!).
The paper builds on my ongoing research on digital technologies and procurement governance, and focuses on the interaction between the strategic goals of procurement centralisation and digitalisation set by the European Commission in its 2017 public procurement strategy.
The paper identifies different ways in which current trends of procurement digitalisation and the challenges in procuring digital technologies push for further procurement centralisation. This is in particular to facilitate the extraction of insights from big data held by central purchasing bodies (CPBs); build public sector digital capabilities; and boost procurement’s regulatory gatekeeping potential. The paper then explores the competition implications of this technology-driven push for further procurement centralisation, in both ‘standard’ and digital markets.
The paper concludes by stressing the need to bring CPBs within the remit of competition law (which I had already advocated eg here), the opportunity to consider allocating CPB data management to a separate competent body under the Data Governance Act, and the related need to develop an effective system of mandatory requirements and external oversight of public sector digitalisation processes, specially to constrain CPBs’ (unbridled) digital regulatory power.
The full working paper reference is: A Sanchez-Graells, Albert, ‘Competition Implications of Procurement Digitalisation and the Procurement of Digital Technologies by Central Purchasing Bodies’ (March 2, 2023), Available at SSRN: https://ssrn.com/abstract=4376037. As always, any feedback most welcome: a.sanchez-graells@bristol.ac.uk.
"Tech fixes for procurement problems?" [Recording]
The recording and slides for yesterday’s webinar on ‘Tech fixes for procurement problems?’ co-hosted by the University of Bristol Law School and the GW Law Government Procurement Programme are now available for catch up if you missed it.
I would like to thank once again Dean Jessica Tillipman (GW Law), Professor Sope Williams (Stellenbosch), and Eliza Niewiadomska (EBRD) for really interesting discussion, and to all participants for their questions. Comments most welcome, as always.
Registration open: TECH FIXES FOR PROCUREMENT PROBLEMS?
As previously announced, on 15 December, I will have the chance to discuss my ongoing research on procurement digitalisation with a stellar panel: Eliza Niewiadomska (EBRD), Jessica Tillipman (GW Law), and Sope Williams (Stellenbosch).
The webinar will provide an opportunity to take a hard look at the promise of tech fixes for procurement problems, focusing on key issues such as:
The ‘true’ potential of digital technologies in procurement.
The challenges arising from putting key enablers in place, such as an adequate big data architecture and access to digital skills in short supply.
The challenges arising from current regulatory frameworks and constraints not applicable to the private sector.
New challenges posed by data governance and cybersecurity risks.
The webinar will be held on December 15, 2022 at 9:00 am EST / 2:00 pm GMT / 3:00 pm CET-SAST. Full details and registration at: https://blogs.gwu.edu/law-govpro/tech-fixes-for-procurement-problems/.

Save the date: 15 Dec, Tech fixes for procurement problems?
If you are interested in procurement digitalisation, please save the date for an online workshop on ‘Tech fixes for procurement problems?’ on 15 December 2022, 2pm GMT. I will have the chance to discuss my ongoing research (scroll down for a few samples) with a stellar panel: Eliza Niewiadomska (EBRD), Jessica Tillipman (GW Law), and Sope Williams (Stellenbosch). We will also have plenty time for a conversation with participants. Do not let other commitments get on the way of joining the discussion!
More details and registration coming soon. For any questions, please email me: a.sanchez-graells@bristol.ac.uk.

Digital procurement governance: drawing a feasibility boundary

In the current context of generalised quick adoption of digital technologies across the public sector and strategic steers to accelerate the digitalisation of public procurement, decision-makers can be captured by techno hype and the ‘policy irresistibility’ that can ensue from it (as discussed in detail here, as well as here).
To moderate those pressures and guide experimentation towards the successful deployment of digital solutions, decision-makers must reassess the realistic potential of those technologies in the specific context of procurement governance. They must also consider which enabling factors must be put in place to harness the potential of the digital technologies—which primarily relate to an enabling big data architecture (see here). Combined, the data requirements and the contextualised potential of the technologies will help decision-makers draw a feasibility boundary for digital procurement governance, which should inform their decisions.
In a new draft chapter (num 7) for my book project, I draw such a technology-informed feasibility boundary for digital procurement governance. This post provides a summary of my main findings, on which I will welcome any comments: a.sanchez-graells@bristol.ac.uk. The full draft chapter is free to download: A Sanchez-Graells, ‘Revisiting the promise: A feasibility boundary for digital procurement governance’ to be included in A Sanchez-Graells, Digital Technologies and Public Procurement. Gatekeeping and experimentation in digital public governance (OUP, forthcoming). Available at SSRN: https://ssrn.com/abstract=4232973.
Data as the main constraint
It will hardly be surprising to stress again that high quality big data is a pre-requisite for the development and deployment of digital technologies. All digital technologies of potential adoption in procurement governance are data-dependent. Therefore, without adequate data, there is no prospect of successful adoption of the technologies. The difficulties in generating an enabling procurement data architecture are detailed here.
Moreover, new data rules only regulate the capture of data for the future. This means that it will take time for big data to accumulate. Accessing historical data would be a way of building up (big) data and speeding up the development of digital solutions. Moreover, in some contexts, such as in relation with very infrequent types of procurement, or in relation to decisions concerning previous investments and acquisitions, historical data will be particularly relevant (eg to deploy green policies seeking to extend the use life of current assets through programmes of enhanced maintenance or refurbishment; see here). However, there are significant challenges linked to the creation of backward-looking digital databases, not only relating to the cost of digitisation of the information, but also to technical difficulties in ensuring the representativity and adequate labelling of pre-existing information.
An additional issue to consider is that a number of governance-relevant insights can only be extracted from a combination of procurement and other types of data. This can include sources of data on potential conflict of interest (eg family relations, or financial circumstances of individuals involved in decision-making), information on corporate activities and offerings, including detailed information on products, services and means of production (eg in relation with licensing or testing schemes), or information on levels of utilisation of public contracts and satisfaction with the outcomes by those meant to benefit from their implementation (eg users of a public service, or ‘internal’ users within the public administration).
To the extent that the outside sources of information are not digitised, or not in a way that is (easily) compatible or linkable with procurement information, some data-based procurement governance solutions will remain undeliverable. Some developments in digital procurement governance will thus be determined by progress in other policy areas. While there are initiatives to promote the availability of data in those settings (eg the EU’s Data Governance Act, the Guidelines on private sector data sharing, or the Open Data Directive), the voluntariness of many of those mechanisms raises important questions on the likely availability of data required to develop digital solutions.
Overall, there is no guarantee that the data required for the development of some (advanced) digital solutions will be available. A careful analysis of data requirements must thus be a point of concentration for any decision-maker from the very early stages of considering digitalisation projects.
Revised potential of selected digital technologies
Once (or rather, if) that major data hurdle is cleared, the possibilities realistically brought by the functionality of digital technologies need to be embedded in the procurement governance context, which results in the following feasibility boundary for the adoption of those technologies.
Robotic Process Automation (RPA)
RPA can reduce the administrative costs of managing pre-existing digitised and highly structured information in the context of entirely standardised and repetitive phases of the procurement process. RPA can reduce the time invested in gathering and cross-checking information and can thus serve as a basic element of decision-making support. However, RPA cannot increase the volume and type of information being considered (other than in cases where some available information was not being taken into consideration due to eg administrative capacity constraints), and it can hardly be successfully deployed in relation to open-ended or potentially contradictory information points. RPA will also not change or improve the processes themselves (unless they are redesigned with a view to deploying RPA).
This generates a clear feasibility boundary for RPA deployment, which will generally have as its purpose the optimisation of the time available to the procurement workforce to engage in information analysis rather than information sourcing and basic checks. While this can clearly bring operational advantages, it will hardly transform procurement governance.
Machine Learning (ML)
Developing ML solutions will pose major challenges, not only in relation to the underlying data architecture (as above), but also in relation to specific regulatory and governance requirements specific to public procurement. Where the operational management of procurement does not diverge from the equivalent function in the (less regulated) private sector, it will be possible to see the adoption or adaptation of similar ML solutions (eg in relation to category spend management). However, where there are regulatory constraints on the conduct of procurement, the development of ML solutions will be challenging.
For example, the need to ensure the openness and technical neutrality of procurement procedures will limit the possibilities of developing recommender systems other than in pre-procured closed lists or environments based on framework agreements or dynamic purchasing systems underpinned by electronic catalogues. Similarly, the intended use of the recommender system may raise significant legal issues concerning eg the exercise of discretion, which can limit their deployment to areas of information exchange or to merely suggestion-based tasks that could hardly replace current processes and procedures. Given the limited utility (or acceptability) of collective filtering recommender solutions (which is the predominant type in consumer-facing private sector uses, such as Netflix or Amazon), there are also constraints on the generality of content-based recommender systems for procurement applications, both at tenderer and at product/service level. This raises a further feasibility issue, as the functional need to develop a multiplicity of different recommenders not only reopens the issue of data sufficiency and adequacy, but also raises questions of (economic and technical) viability. Recommender systems would mostly only be susceptible of feasible adoption in highly centralised procurement settings. This could create a push for further procurement centralisation that is not neutral from a governance perspective, and that can certainly generate significant competition issues of a similar nature, but perhaps a different order of magnitude, than procurement centralisation in a less digitally advanced setting. This should be carefully considered, as the knock-on effects of the implementation of some ML solutions may only emerge down the line.
Similarly, the development and deployment of chatbots is constrained by specific regulatory issues, such as the need to deploy closed domain chatbots (as opposed to open domain chatbots, ie chatbots connected to the Internet, such as virtual assistants built into smartphones), so that the information they draw from can be controlled and quality assured in line with duties of good administration and other legal requirements concerning the provision of information within tender procedures. Chatbots are suited to types of high-volume information-based queries only. They would have limited applicability in relation to the specific characteristics of any given procurement procedure, as preparing the specific information to be used by the chatbot would be a challenge—with the added functionality of the chatbot being marginal. Chatbots could facilitate access to pre-existing and curated simple information, but their functionality would quickly hit a ceiling as the complexity of the information progressed. Chatbots would only be able to perform at a higher level if they were plugged to a knowledge base created as an expert system. But then, again, in that case their added functionality would be marginal. Ultimately, the practical space for the development of chatbots is limited to low added value information access tasks. Again, while this can clearly bring operational advantages, it will hardly transform procurement governance.
ML could facilitate the development and deployment of ‘advanced’ automated screens, or red flags, which could identify patterns of suspicious behaviour to then be assessed against the applicable rules (eg administrative and criminal law in case of corruption, or competition law, potentially including criminal law, in case of bid rigging) or policies (eg in relation to policy requirements to comply with specific targets in relation to a broad variety of goals). The trade off in this type of implementation is between the potential (accuracy) of the algorithmic screening and legal requirements on the explainability of decision-making (as discussed in detail here). Where the screens were not used solely for policy analysis, but acting on the red flag carried legal consequences (eg fines, or even criminal sanctions), the suitability of specific types of ML solutions (eg unsupervised learning solutions tantamount to a ‘black box’) would be doubtful, challenging, or altogether excluded. In any case, the development of ML screens capable of significantly improving over RPA-based automation of current screens is particularly dependent on the existence of adequate data, which is still proving an insurmountable hurdle in many an intended implementation (as above).
Distributed ledger technology (DLT) systems and smart contracts
Other procurement governance constraints limit the prospects of wholesale adoption of DLT (or blockchain) technologies, other than for relatively limited information management purposes. The public sector can hardly be expected to adopt DLT solutions that are not heavily permissioned, and that do not include significant safeguards to protect sensitive, commercially valuable, and other types of information that cannot be simply put in the public domain. This means that the public sector is only likely to implement highly centralised DLT solutions, with the public sector granting permissions to access and amend the relevant information. While this can still generate some (degrees of) tamper-evidence and permanence of the information management system, the net advantage is likely to be modest when compared to other types of secure information management systems. This can have an important bearing on decisions whether DLT solutions meet cost effectiveness or similar criteria of value for money controlling their piloting and deployment.
The value proposition of DLT solutions could increase if they enabled significant procurement automation through smart contracts. However, there are massive challenges in translating procurement procedures to a strict ‘if/when ... then’ programmable logic, smart contracts have limited capability that is not commensurate with the volumes and complexity of procurement information, and their development would only be justified in contexts where a given smart contract (ie specific programme) could be used in a high number of procurement procedures. This limits its scope of applicability to standardised and simple procurement exercises, which creates a functional overlap with some RPA solutions. Even in those settings, smart contracts would pose structural problems in terms of their irrevocability or automaticity. Moreover, they would be unable to generate off-chain effects, and this would not be easily sorted out even with the inclusion of internet of things (IoT) solutions or software oracles. This comes to largely restrict smart contracts to an information exchange mechanism, which does not significantly increase the value added by DLT plus smart contract solutions for procurement governance.
Conclusion
To conclude, there are significant and difficult to solve hurdles in generating an enabling data architecture, especially for digital technologies that require multiple sources of information or data points regarding several phases of the procurement process. Moreover, the realistic potential of most technologies primarily concerns the automation of tasks not involving data analysis of the exercise of procurement discretion, but rather relatively simple information cross-checks or exchanges. Linking back to the discussion in the earlier broader chapter (see here), the analysis above shows that a feasibility boundary emerges whereby the adoption of digital technologies for procurement governance can make contributions in relation to its information intensity, but not easily in relation to its information complexity, at least not in the short to medium term and not in the absence of a significant improvement of the required enabling data architecture. Perhaps in more direct terms, in the absence of a significant expansion in the collection and curation of data, digital technologies can allow procurement governance to do more of the same or to do it quicker, but it cannot enable better procurement driven by data insights, except in relatively narrow settings. Such settings are characterised by centralisation. Therefore, the deployment of digital technologies can be a further source of pressure towards procurement centralisation, which is not a neutral development in governance terms.
This feasibility boundary should be taken into account in considering potential use cases, as well as serve to moderate the expectations that come with the technologies and that can fuel ‘policy irresistibility’. Further, it should be stressed that those potential advantages do not come without their own additional complexities in terms of new governance risks (eg data and data systems integrity, cybersecurity, skills gaps) and requirements for their mitigation. These will be explored in the next stage of my research project.
Digital technologies, hype, and public sector capability

© Martin Brandt / Flickr.
By Albert Sanchez-Graells (@How2CrackANut) and Michael Lewis (@OpsProf).*
The public sector’s reaction to digital technologies and the associated regulatory and governance challenges is difficult to map, but there are some general trends that seem worrisome. In this blog post, we reflect on the problematic compound effects of technology hype cycles and diminished public sector digital technology capability, paying particular attention to their impact on public procurement.
Digital technologies, smoke, and mirrors
There is a generalised over-optimism about the potential of digital technologies, as well as their likely impact on economic growth and international competitiveness. There is also a rush to ‘look digitally advanced’ eg through the formulation of ‘AI strategies’ that are unlikely to generate significant practical impacts (more on that below). However, there seems to be a big (and growing?) gap between what countries report (or pretend) to be doing (eg in reports to the OECD AI observatory, or in relation to any other AI readiness ranking) and what they are practically doing. A relatively recent analysis showed that European countries (including the UK) underperform particularly in relation to strategic aspects that require detailed work (see graph). In other words, there are very few countries ready to move past signalling a willingness to jump onto the digital tech bandwagon.
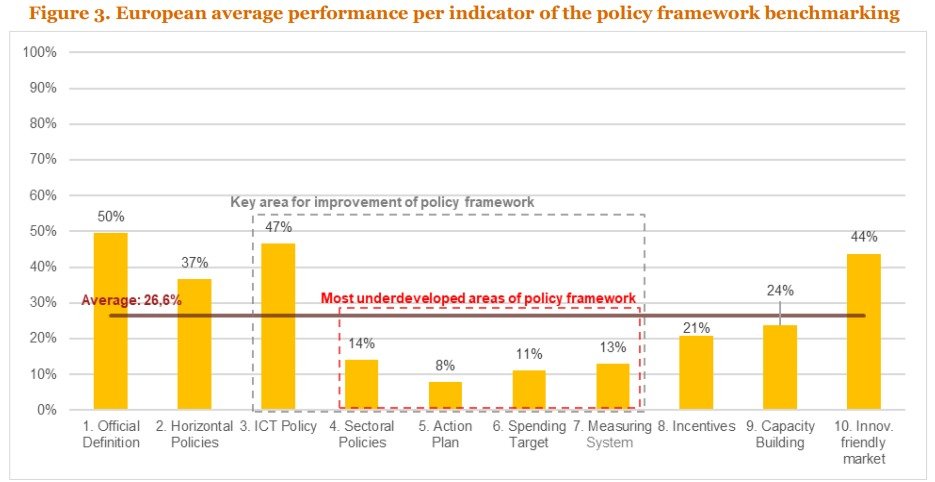
Source: PWC, The strategic use of public procurement for innovation in the digital economy (2021: 9).
Some of that over-optimism stems from limited public sector capability to understand the technologies themselves (as well as their implications), which leads to naïve or captured approaches to policymaking (on capture, see the eye-watering account emerging from the #Uberfiles). Given the closer alignment (or political meddling?) of policymakers with eg research funding programmes, including but not limited to academic institutions, naïve or captured approaches impact other areas of ‘support’ for the development of digital technologies. This also trickles down to procurement, as the ‘purchasing’ of digital technologies with public money is seen as a (not very subtle) way of subsidising their development (nb. there are many proponents of that approach, such as Mazzucato, as discussed here). However, this can also generate further space for capture, as the same lack of capability that affects high(er) level policymaking also affects funding organisations and ‘street level’ procurement teams. This results in a situation where procurement best practices such as market engagement result in the ‘art of the possible’ being determined by private industry. There is rarely co-creation of solutions, but too often a capture of procurement expenditure by entrepreneurs.
Limited capability, difficult assessments, and dependency risk
Perhaps the universalist techno-utopian framing (cost savings and efficiency and economic growth and better health and new service offerings, etc.) means it is increasingly hard to distinguish the specific merits of different digitalisation options – and the commercial interests that actively hype them. It is also increasingly difficult to carry out effective impact assessments where the (overstressed) benefits are relatively narrow and short-termist, while the downsides of technological adoption are diffuse and likely to only emerge after a significant time lag. Ironically, this limited ability to diagnose ‘relative’ risks and rewards is further exacerbated by the diminishing technical capability of the state: a negative mirror to Amazon’s flywheel model for amplifying capability. Indeed, as stressed by Bharosa (2022): “The perceptions of benefits and risks can be blurred by the information asymmetry between the public agencies and GovTech providers. In the case of GovTech solutions using new technologies like AI, Blockchain and IoT, the principal-agent problem can surface”.
As Colington (2021) points out, despite the “innumerable papers in organisation and management studies” on digitalisation, there is much less understanding of how interests of the digital economy might “reconfigure” public sector capacity. In studying Denmark’s policy of public sector digitalisation – which had the explicit intent of stimulating nascent digital technology industries – she observes the loss of the very capabilities necessary “for welfare states to develop competences for adapting and learning”. In the UK, where it might be argued there have been attempts, such as the Government Digital Services (GDS) and NHS Digital, to cultivate some digital skills ‘in-house’, the enduring legacy has been more limited in the face of endless demands for ‘cost saving’. Kattel and Takala (2021) for example studied GDS and noted that, despite early successes, they faced the challenge of continual (re)legitimization and squeezed investment; especially given the persistent cross-subsidised ‘land grab’ of platforms, like Amazon and Google, that offer ‘lower cost and higher quality’ services to governments. The early evidence emerging from the pilot algorithmic transparency standard seems to confirm this trend of (over)reliance on external providers, including Big Tech providers such as Microsoft (see here).
This is reflective of Milward and Provan’s (2003) ‘hollow state’ metaphor, used to describe "the nature of the devolution of power and decentralization of services from central government to subnational government and, by extension, to third parties – nonprofit agencies and private firms – who increasingly manage programs in the name of the state.” Two decades after its formulation, the metaphor is all the more applicable, as the hollowing out of the State is arguably a few orders of magnitude larger due the techno-centricity of reforms in the race towards a new model of digital public governance. It seems as if the role of the State is currently understood as being limited to that of enabler (and funder) of public governance reforms, not solely implemented, but driven by third parties—and primarily highly concentrated digital tech giants; so that “some GovTech providers can become the next Big Tech providers that could further exploit the limited technical knowledge available at public agencies [and] this dependency risk can become even more significant once modern GovTech solutions replace older government components” (Bharosa, 2022). This is a worrying trend, as once dominance is established, the expected anticompetitive effects of any market can be further multiplied and propagated in a setting of low public sector capability that fuels risk aversion, where the adage “Nobody ever gets fired for buying IBM” has been around since the 70s with limited variation (as to the tech platform it is ‘safe to engage’).
Ultimately, the more the State takes a back seat, the more its ability to steer developments fades away. The rise of a GovTech industry seeking to support governments in their digital transformation generates “concerns that GovTech solutions are a Trojan horse, exploiting the lack of technical knowledge at public agencies and shifting decision-making power from public agencies to market parties, thereby undermining digital sovereignty and public values” (Bharosa, 2022). Therefore, continuing to simply allow experimentation in the GovTech market without a clear strategy on how to reign the industry in—and, relatedly, how to build the public sector capacity needed to do so as a precondition—is a strategy with (exponentially) increasing reversal costs and an unclear tipping point past which meaningful change may simply not be possible.
Public sector and hype cycle
Being more pragmatic, the widely cited, if impressionistic, “hype cycle model” developed by Gartner Inc. provides additional insights. The model presents a generalized expectations path that new technologies follow over time, which suggests that new industrial technologies progress through different stages up to a peak that is followed by disappointment and, later, a recovery of expectations.

Although intended to describe aggregate technology level dynamics, it can be useful to consider the hype cycle for public digital technologies. In the early phases of the curve, vendors and potential users are actively looking for ways to create value from new technology and will claim endless potential use cases. If these are subsequently piloted or demonstrated – even if ‘free’ – they are exciting and visible, and vendors are keen to share use cases, they contribute to creating hype. Limited public sector capacity can also underpin excitement for use cases that are so far removed from their likely practical implementation, or so heavily curated, that they do not provide an accurate representation of how the technology would operate at production phase in the generally messy settings of public sector activity and public sector delivery. In phases such as the peak of inflated expectations, only organisations with sufficient digital technology and commercial capabilities can see through sophisticated marketing and sales efforts to separate the hype from the true potential of immature technologies. The emperor is likely to be naked, but who’s to say?
Moreover, as mentioned above, international organisations one step (upwards) removed from the State create additional fuel for the hype through mapping exercises and rankings, which generate a vicious circle of “public sector FOMO” as entrepreneurial bureaucrats and politicians are unlikely to want to be listed bottom of the table and can thus be particularly receptive to hyped pitches. This can leverage incentives to support *almost any* sort of tech pilots and implementations just to be seen to do something ‘innovative’, or to rush through high-risk implementations seeking to ‘cash in’ on the political and other rents they can (be spun to) generate.
However, as emerging evidence shows (AI Watch, 2022), there is a big attrition rate between announced and piloted adoptions, and those that are ultimately embedded in the functioning of the public sector in a value-adding manner (ie those that reach the plateau of productivity stage in the cycle). Crucially, the AI literacy and skills in the staff involved in the use of the technology post-pilot are one of the critical challenges to the AI implementation phase in the EU public sector (AI Watch, 2021). Thus, early moves in the hype curve are unlikely to translate into sustainable and expectations-matching deployments in the absence of a significant boost of public sector digital technology capabilities. Without committed long-term investment in that capability, piloting and experimentation will rarely translate into anything but expensive pet projects (and lucrative contracts).
Locking the hype in: IP, data, and acquisitions markets
Relatedly, the lack of public sector capacity is a foundation for eg policy recommendations seeking to avoid the public buyer acquiring (and having to manage) IP rights over the digital technologies it funds through procurement of innovation (see eg the European Commission’s policy approach: “There is also a need to improve the conditions for companies to protect and use IP in public procurement with a view to stimulating innovation and boosting the economy. Member States should consider leaving IP ownership to the contractors where appropriate, unless there are overriding public interests at stake or incompatible open licensing strategies in place” at 10).
This is clear as mud (eg what does overriding public interest mean here?) but fails to establish an adequate balance between public funding and public access to the technology, as well as generating (unavoidable?) risks of lock-in and exacerbating issues of lack of capacity in the medium and long-term. Not only in terms of re-procuring the technology (see related discussion here), but also in terms of the broader impact this can have if the technology is propagated to the private sector as a result of or in relation to public sector adoption.
Linking this recommendation to the hype curve, such an approach to relying on proprietary tech with all rights reserved to the third-party developer means that first mover advantages secured by private firms at the early stages of the emergence of a new technology are likely to be very profitable in the long term. This creates further incentives for hype and for investment in being the first to capture decision-makers, which results in an overexposure of policymakers and politicians to tech entrepreneurs pushing hard for (too early) adoption of technologies.
The exact same dynamic emerges in relation to access to data held by public sector entities without which GovTech (and other types of) innovation cannot take place. The value of data is still to be properly understood, as are the mechanisms that can ensure that the public sector obtains and retains the value that data uses can generate. Schemes to eg obtain value options through shares in companies seeking to monetise patient data are not bullet-proof, as some NHS Trusts recently found out (see here, and here paywalled). Contractual regulation of data access, data ownership and data retention rights and obligations pose a significant challenge to institutions with limited digital technology capabilities and can compound IP-related lock-in problems.
A final further complication is that the market for acquisitions of GovTech and other digital technologies start-ups and scale-ups is very active and unpredictable. Even with standard levels of due diligence, public sector institutions that had carefully sought to foster a diverse innovation ecosystem and to avoid contracting (solely) with big players may end up in their hands anyway, once their selected provider leverages their public sector success to deliver an ‘exit strategy’ for their founders and other (venture capital) investors. Change of control clauses clearly have a role to play, but the outside alternatives for public sector institutions engulfed in this process of market consolidation can be limited and difficult to assess, and particularly challenging for organisations with limited digital technology and associated commercial capabilities.
Procurement at the sharp end
Going back to the ongoing difficulty (and unwillingness?) in regulating some digital technologies, there is a (dominant) general narrative that imposes a ‘balanced’ approach between ensuring adequate safeguards and not stifling innovation (with some countries clearly erring much more on the side of caution, such as the UK, than others, such as the EU with the proposed EU AI Act, although the scope of application of its regulatory requirements is narrower than it may seem). This increasingly means that the tall order task of imposing regulatory constraints on the digital technologies and the private sector companies that develop (and own them) is passed on to procurement teams, as the procurement function is seen as a useful regulatory mechanism (see eg Select Committee on Public Standards, Ada Lovelace Institute, Coglianese and Lampmann (2021), Ben Dor and Coglianese (2022), etc but also the approach favoured by the European Commission through the standard clauses for the procurement of AI).
However, this approach completely ignores issues of (lack of) readiness and capability that indicate that the procurement function is being set up to fail in this gatekeeping role (in the absence of massive investment in upskilling). Not only because it lacks the (technical) ability to figure out the relevant checks and balances, and because the levels of required due diligence far exceed standard practices in more mature markets and lower risk procurements, but also because the procurement function can be at the sharp end of the hype cycle and (pragmatically) unable to stop the implementation of technological deployments that are either wasteful or problematic from a governance perspective, as public buyers are rarely in a position of independent decision-making that could enable them to do so. Institutional dynamics can be difficult to navigate even with good insights into problematic decisions, and can be intractable in a context of low capability to understand potential problems and push back against naïve or captured decisions to procure specific technologies and/or from specific providers.
Final thoughts
So, as a generalisation, lack of public sector capability seems to be skewing high level policy and limiting the development of effective plans to roll it out, filtering through to incentive systems that will have major repercussions on what technologies are developed and procured, with risks of lock-in and centralisation of power (away from the public sector), as well as generating a false comfort in the ability of the public procurement function to provide an effective route to tech regulation. The answer to these problems is both evident, simple, and politically intractable in view of the permeating hype around new technologies: more investment in capacity building across the public sector.
This regulatory answer is further complicated by the difficulty in implementing it in an employment market where the public sector, its reward schemes and social esteem are dwarfed by the high salaries, flexible work conditions and allure of the (Big) Tech sector and the GovTech start-up scene. Some strategies aimed at alleviating the generalised lack of public sector capability, e.g. through a GovTech platform at the EU level, can generate further risks of reduction of (in-house) public sector capability at State (and regional, local) level as well as bottlenecks in the access of tech to the public sector that could magnify issues of market dominance, lock-in and over-reliance on GovTech providers (as discussed in Hoekstra et al, 2022).
Ultimately, it is imperative to build more digital technology capability in the public sector, and to recognise that there are no quick (or cheap) fixes to do so. Otherwise, much like with climate change, despite the existence of clear interventions that can mitigate the problem, the hollowing out of the State and the increasing overdependency on Big Tech providers will be a self-fulfilling prophecy for which governments will have no one to blame but themselves.
___________________________________
* We are grateful to Rob Knott (@Procure4Health) for comments on an earlier draft. Any remaining errors and all opinions are solely ours.
Protecting procurement's AI gatekeeping role in domestic law, and trade agreements? -- re Irion (2022)

© r2hox / Flickr.
The increasing recognition of the role of procurement as AI gatekeeper, or even as AI (pseudo)regulator, is quickly galvanising and leading to proposals to enshrine it in domestic legislation. For example, in the Parliamentary process of the UK’s 2022 Procurement Bill, an interesting amendment has surfaced. The proposal by Lord Clement-Jones would see the introduction of the following clause:
“Procurement principles: automated decision-making and data ethics
In carrying out a procurement, a contracting authority must ensure the safe, sustainable and ethical use of automated or algorithmic decision-making systems and the responsible and ethical use of data.”
The purpose of the clause would be to ensure ‘that the ethical use of automated decision-making and data is taken into account when carrying out a procurement.’ This is an interesting proposal that would put the procuring entity, even if not the future user of the AI (?), in the legally-mandated position of custodian or gatekeeper for trustworthy AI—which, of course, depending on future interpretation could be construed narrowly or expansively (e.g. on whether to limit it to automated decision-making, or extend it to decision-making support algorithmic systems?).
This would go beyond current regulatory approaches in the UK, where this gatekeeping position arises from soft law, such as the 2020 Guidelines for AI procurement. It would probably require significant additional guidance on how this role is to be operationalised, presumably through algorithmic impact assessments and/or other forms of ex ante intervention, such as the imposition of (standard) requirements in the contracts for AI procurement, or even ex ante algorithmic audits.
These requirements would be in line with influential academic proposals [e.g. M Martini, ‘Regulating Algorithms. How to Demystify the Alchemy of Code?’ in M Ebers & S Navas, Algorithms and Law (CUP 2020) 100, 115, and 120-22], as well as largely map onto voluntary compliance with EU AI Act’s requirements for high-risk AI uses (which is the approach also currently followed in the proposal for standard contractual clauses for the procurement of AI by public organisations being developed under the auspices of the European Commission).
One of the key practical considerations for a contracting authority to be able to discharge this gatekeeping role (amongst many others on expertise, time, regulatory capture, etc) is access to source code (also discussed here). Without accessing the source code, the contracting authority can barely understand the workings of the (to be procured) algorithms. Therefore, it is necessary to preserve the possibility of demanding access to source code for all purposes related to the procurement (and future re-procurement) of AI (and other software).
From this perspective, it is interesting to take a look at current developments in the protection of source code at the level of international trade regulation. An interesting paper coming out of the on-going FAccT conference addresses precisely this issue: K Irion, ‘Algorithms Off-limits? If digital trade law restricts access to source code of software then accountability will suffer’ (2022) FAccT proceedings 1561-70.
Irion’s paper provides a good overview of the global efforts to protect source code in the context of trade regulation, maps how free trade agreements are increasingly used to construct an additional layer of protection for software source code (primarily from forced technology transfer), and rightly points at risks of regulatory lock-out or pre-emption depending on the extent to which source code confidentiality is pierced for a range of public interest cases.
What is most interesting for the purposes of our discussion is that source code protection is not absolute, but explicitly deactivated in the context of public procurement in all emerging treaties (ibid, 1564-65). Generally, the treaties either do not prohibit, or have an explicit exception for, source code transfers in the context of commercially negotiated contracts—which can in principle include contracts with the public sector (although the requirement for negotiation could be a hurdle in some scenarios). More clearly, under what can be labelled as the ‘EU approach’, there is an explicit carve-out for ‘the voluntary transfer of or granting of access to source code for instance in the context of government procurement’ (see Article 8.73 EU-Japan EPA; similarly, Article 207 EU–UK TCA; and Article 9 EU-Mexico Agreement in principle). This means that the EU (and other major jurisdictions) are very clear in their (intentional?) approach to preserve the gatekeeping role of procurement by enabling contracting authorities to require access to software source code.
Conversely, the set of exceptions generally emerging in source code protection via trade regulation can be seen as insufficient to ensure high levels of algorithmic governance resulting from general rules imposing ex ante interventions. Indeed, Irion argues that ‘Legislation that mandates conformity assessments, certification schemes or standardized APIs would be inconsistent with the protection of software source code inside trade law’ (ibid, 1564). This is debatable, as a less limiting interpretation of the relevant exceptions seems possible, in particular as they concern disclosure for regulatory examination (with the devil, of course, being in the detail of what is considered a regulatory body and how ex ante interventions are regulated in a particular jurisdiction).
If this stringent understanding of the possibility to mandate regulatory compliance with this being seen as a violation of the general prohibition on source code disclosure for the purposes of its ‘tradability’ in a specific jurisdiction becomes the prevailing interpretation of the relevant FTAs, and regulatory interventions are thus constrained to ex post case-by-case investigations, it is easy to see how the procurement-related exceptions will become an (even more important) conduit for ex ante access to software source code for regulatory purposes, in particular where the AI is to be deployed in the context of public sector activity.
This is thus an interesting area of digital trade regulation to keep an eye on. And, more generally, it will be important to make sure that the AI gatekeeping role assigned to the procurement function is aligned with international obligations resulting from trade liberalisation treaties—which would require a general propagation of the ‘EU approach’ to explicitly carving out procurement-related disclosures.
Procurement recommenders: a response by the author (García Rodríguez)
It has been refreshing to receive a detailed response by the lead author of one of the papers I recently discussed in the blog (see here). Big thanks to Manuel García Rodríguez for following up and for frank and constructive engagement. His full comments are below. I think they will help round up the discussion on the potential, constraints and data-dependency of procurement recommender systems.
Thank you Prof. Sánchez Graells for your comments, it has been a rewarding reading. Below I present my point of view to continue taking an in-depth look about the topic.
Regarding the percentage of success of the recommender, a major initial consideration is that the recommender is generic. It means, it is not restricted to a type of contract, CPV codes, geographical area, etc. It is a recommender that uses all types of Spanish tenders, from any CPV and over 6 years (see table 3). This greatly influences the percentage of success because it is the most difficult scenario. An easier scenario would have restricted the browser to certain geographic areas or CPVs, for example. In addition, 102,000 tenders have been used to this study and, presumably, they are not enough for a search engine which learn business behaviour patterns from historical tenders (more tenders could not be used due to poor data quality).
Regarding the comment that ‘the recommender is an effective tool for society because it enables and increases the bidders participation in tenders with less effort and resources‘. With this phrase we mean that the Administration can have an assistant to encourage participation (in the tenders which are negotiations with or without prior notice) or, even, in which the civil servants actively search for companies and inform those companies directly. I do not know if the public contracting laws of the European countries allow to search for actively and inform directly but it would be the most efficient and reasonable. On the other hand, a good recommender (one that has a high percentage of accuracy) can be an analytical tool to evaluate the level of competition by the contracting authorities. That is, if the tenders of a contracting authority attract very little competition but the recommender finds many potential participating companies, it means that the contracting authority can make its tenders more attractive for the market.
Regarding the comment that “It is also notable that the information of the Companies Register is itself not (and probably cannot be, period) checked or validated, despite the fact that most of it is simply based on self-declarations.” The information in the Spanish Business Register are the annual accounts of the companies, audited by an external entity. I do not know the auditing laws of the different countries. Therefore, I think that the reliability of the data is quite high in our article.
Regarding the first problematic aspect that you indicate: “The first one is that the recommender seems by design incapable of comparing the functional capabilities of companies with very different structural characteristics, unless the parameters for the filtering are given such range that the basket of recommendations approaches four digits”. There will always be the difficulty of comparing companies and defining when they are similar. That analysis should be done by economists, engineers can contribute little. There is also the limitation of business data, the information of the Business Register is usually paywalled and limited to certain fields, as is the case with the Spanish Business Registry. For these reasons, we recognise in the article that it is a basic approach, and it should be modified the filters/rules in the future: “Creating this profile to search similar companies is a very complex issue, which has been simplified. For this reason, the searching phase (3) has basic filters or rules. Moreover, it is possible to modify or add other filters according to the available company dataset used in the aggregation phase”.
Regarding the second problematic aspect that you indicate: “The second issue is that a recommender such as this one seems quite vulnerable to the risk of perpetuating and exacerbating incumbency advantages, and/or of consolidating geographical market fragmentation (given the importance of eg distance, which cannot generate the expected impact on eg costs in all industries, and can increasingly be entirely irrelevant in the context of digital/remote delivery).” This will not happen in the medium and long term because the recommender will adapt to market conditions. If there are companies that win bids far away, the algorithm will include that new distance range in its search. It will always be based on the historical winner companies (and the rest of the bidders if we have that information). You cannot ask a machine learning algorithm (the one used in this article) to make predictions not based on the previous winners and historical market patterns.
I totally agree with your final comment: “It would in my view be preferable to start by designing the recommender system in a way that makes theoretical sense and then make sure that the required data architecture exists or is created.” Unfortunately, I did not find any articles that discuss this topic. Lawyers, economists and engineers must work together to propose solid architectures. In this article we want to convince stakeholders that it is possible to create software tools such as a bidder recommender and the importance of public procurement data and the company’s data in the Business Registers for its development.
Thank you for your critical review. Different approaches are needed to improve on the important topic of public procurement.
Procurement recommender systems: how much better before we trust them? -- re García Rodríguez et al (2020)

© jm3 on Flickr.
How great would it be for a public buyer if an algorithm could identify the likely best bidder/s for a contract it sought to award? Pretty great, agreed.
For example, it would allow targeted advertising or engagement of public procurement opportunities to make sure those ‘best suited’ bidders came forward, or to start negotiations where this is allowed. It could also enable oversight bodies, such as competition authorities, to screen for odd (anti)competitive situations where well-placed providers did not bid for the contract, or only did in worse than expected conditions. If the algorithm was flipped, it would also allow potential bidders to assess for which tenders they are particularly well suited (or not).
It is thus not surprising that there are commercial attempts being developed (eg here) and interesting research going on trying to develop such recommender systems—which, at root, work similarly to recommender systems used in e-commerce (Amazon) or digital content platforms (Netflix, Spotify), in the sense that they try to establish which of the potential providers are most likely to satisfy user needs.
An interesting paper
On this issue, on which there has been some research for at least a decade (see here), I found this paper interesting: García Rodríguez et al, ‘Bidders Recommender for Public Procurement Auctions Using Machine Learning: Data Analysis, Algorithm, and Case Study with Tenders from Spain’ (2020) Complexity Art 8858258.
The paper is interesting in the way it builds the recommender system. It follows three steps. First, an algorithm trained on past tenders is used to predict the winning bidder for a new tender, given some specific attributes of the contract to be awarded. Second, the predicted winning bidder is matched with its data in the Companies Register, so that a number of financial, workforce, technical and location attributes are linked to the prediction. Third and final, the recommender system is used to identify companies similar to the predicted winner. Such identification is based on similarities with the added attributes of the predicted winner, which are subject to some basic filters or rules. In other words, the comparison is carried out at supplier level, not directly in relation to the object of the contract.
Importantly, such filters to sieve through the comparison need to be given numerical values and that is done manually (i.e. set at rather random thresholds, which in relation to some categories, such as technical specialism, make little intuitive sense). This would in principle allow the user of the recommender system to tailor the parameters of the search for recommended bidders.
In the specific case study developed in the paper, the filters are:
Economic resources to finance the project (i.e. operating income, EBIT and EBITDA);
Human resources to do the work (i.e. number of employees):
Specialised work which the company can do (based on code classification: NACE2, IAE, SIC, and NAICS); and
Geographical distance between the company’s location and the tender’s location.
Notably, in the case study, distance ‘is a fundamental parameter. Intuitively, the proximity has business benefits such as lower costs’ (at 8).
The key accuracy metric for the recommender system is whether it is capable of identifying the actual winner of a contract as the likely winning bidder or, failing that, whether it is capable of including the actual winner within a basket of recommended bidders. Based on the available Spanish data, the performance of the recommender system is rather meagre.
The poor results can be seen in the two scenarios developed in the paper. In scenario 1, the training and test data are split 80:20 and the 20% is selected randomly. In scenario 2, the data is also split 80:20, but the 20% test data is the most recent one. As the paper stresses, ‘the second scenario is more appropriate to test a real engine search’ (at 13), in particular because the use of the recommender will always be ‘for the next tender’ after the last one included in the relevant dataset.
For that more realistic scenario 2, the recommender has an accuracy of 10.25% in correctly identifying the actual winner, and this only raises to 23.12% if the recommendation includes a basket of five companies. Even for the more detached from reality scenario 1, the accuracy of a single prediction is only 17.07%, and this goes up to 31.58% for 5-company recommendations. The most accurate performance with larger baskets of recommended companies only reaches 38.52% in scenario 1, and 30.52% in scenario 2, although the much larger number of recommended companies (approximating 1,000) also massively dilutes the value of the information.
Comments
So, with the available information, the best performance of the recommender system creates about 1 in 10 chances of correctly identifying the most suitable provider, or 1 in 5 chances of having it included in a basket of 5 recommendations. Put the other way, the best performance of the realistic recommender is that it fails to identify the actual winner for a tender 9 out of 10 times, and it still fails 4 out of 5 times when it is given five chances.
I cannot say how this compares with non-automated searches based on looking at relevant company directories, other sources of industry intelligence or even the anecdotal experience of the public buyer, but these levels of accuracy could hardly justify the adoption of the recommender.
In that regard, the optimistic conclusion of the paper (‘the recommender is an effective tool for society because it enables and increases the bidders participation in tenders with less effort and resources‘ at 17) is a little surprising.
The discussion of the limitations of the recommender system sheds some more light:
The main limitation of this research is inherent to the design of the recommender’s algorithm because it necessarily assumes that winning companies will behave as they behaved in the past. Companies and the market are living entities which are continuously changing. On the other hand, only the identity of the winning company is known in the Spanish tender dataset, not the rest of the bidders. Moreover, the fields of the company’s dataset are very limited. Therefore, there is little knowledge about the profile of other companies which applied for the tender. Maybe in other countries the rest of the bidders are known. It would be easy to adapt the bidder recommender to this more favourable situation (at 17).
The issue of the difficulty of capturing dynamic behaviour is well put. However, there are more problems (below) and the issue of disclosure of other participants in the tender is not straightforwardly to the benefit of a more accurate recommender system, unless there was not only disclosure of other bidders but also of the full evaluations of their tenders, which is an unlikely scenario in practice.
There is also the unaddressed issue of whether it makes sense to compare the specific attributes selected in the study, which it mostly does not, but is driven by the available data.
What is ultimately clear from the paper is that the data required for the development of a useful recommender is simply not there, either at all or with sufficient quality.
For example, it is notable that due to data quality issues, the database of past tenders shrinks from 612,090 recorded to 110,987 useable tenders, which further shrink to 102,087 due to further quality issues in matching the tender information with the Companies Register.
It is also notable that the information of the Companies Register is itself not (and probably cannot be, period) checked or validated, despite the fact that most of it is simply based on self-declarations. There is also an issue with the lag with which information is included and updated in the Companies Register—e.g. under Spanish law, company accounts for 2021 will only have to be registered over the summer of 2022, which means that a use of the recommender in late 2022 would be relying on information that is already a year old (as the paper itself hints, at 14).
And I also have the inkling that recommender systems such as this one would be problematic in at least two aspects, even if all the necessary data was available.
The first one is that the recommender seems by design incapable of comparing the functional capabilities of companies with very different structural characteristics, unless the parameters for the filtering are given such range that the basket of recommendations approaches four digits. For example, even if two companies were the closest ones in terms of their specialist technical competence (even if captured only by the very coarse and in themselves problematic codes used in the model)—which seems to be the best proxy for identifying suitability to satisfy the functional needs of the public buyer—they could significantly differ in everything else, especially if one of them is a start-up. Whether the recommender would put both in the same basket (of a useful size) is an empirical question, but it seems extremely unlikely.
The second issue is that a recommender such as this one seems quite vulnerable to the risk of perpetuating and exacerbating incumbency advantages, and/or of consolidating geographical market fragmentation (given the importance of eg distance, which cannot generate the expected impact on eg costs in all industries, and can increasingly be entirely irrelevant in the context of digital/remote delivery).
So, all in all, it seems like the development of recommender systems needs to be flipped on its head if data availability is driving design. It would in my view be preferable to start by designing the recommender system in a way that makes theoretical sense and then make sure that the required data architecture exists or is created. Otherwise, the adoption of suboptimal recommender systems would not only likely generate significant issues of technical debt (for a thorough warning, see Sculley et al, ‘Hidden Technical Debt in Machine Learning Systems‘ (2015)), but also risk significantly worsening the quality (and effectiveness) of procurement decision-making. And any poor implementation in ‘real life’ would deal a sever blow to the prospects of sustainable adoption of digital technologies to support procurement decision-making.